![Waste generation in various fields of industrial chemistry.[23]](/storage/images/resized/2cQZUpcr4Vl6OFTMttzbx9DAwfdV7G9yuFrRpTgu_xl.webp)
![Applications of enzymes as biocatalysts [33-39]](/storage/images/resized/DUveVSGByhPlKlMGdqxOy5bAZOZaPxOyOlTmKl1B_xl.webp)
![Specific activity of feed enzyme preparations on various substrates.[146]](/storage/images/resized/qL0aXiVdd7ZiP8j2oaRM7cEygEH4PtWm5kSp8LAI_xl.webp)
![Component composition of feed enzyme preparations.[146]](/storage/images/resized/Kh88gbsnyviqZ0g4u3AgU7R0i0NdufgfLX7FFESI_xl.webp)
![Structure of the luciferase from Luciola mingrelica (Uniprot Q26304). The amino acid residues subjected to site-directed mutagenesis are shown by spheres. The Figure was created by the authors using published data.[113, 119]](/storage/images/resized/pJ0nzLegqmmjZyrtcGC6HyzWCZknW835JvW8T6uG_xl.webp)
Keywords
Abstract
The review analyzes recent advances, challenges, and practical applications in the field of enzymes within the framework of chemical enzymology and enzyme engineering. The achievements in the fundamental understanding of molecular mechanisms of the catalytic cycle of enzymatic reactions made using quantum mechanics/molecular mechanics methods with supercomputer technologies and bioinformatic approaches are considered. The design of protein biocatalysts with new properties is a fundamentally significant methodology of the bioengineering approach to solving practical problems, which is demonstrated by a number of examples. The increasing role of biocatalysis in medicine and biomedical research is illustrated by addressing the problems of antibiotic synthesis and overcoming antibiotic resistance of bacteria, mechanisms of neurodegenerative diseases and development of drugs to treat Alzheimer's disease, biocatalytic processes of DNA repair and the role of mechanisms of functioning of heme peroxidases in the human body. The use of enzymes to degrade endogenous and exogenous toxicants has been greatly developed in recent decades. The advances and problems of using enzymes in therapy and drug delivery are analyzed. The fundamental role of enzymes in modern analysis and diagnosis is noted. The review considers a new trend in the development of bioanalytical methods using aptamers, multi-analysis systems on biochips, surface-enhanced Raman scattering systems, and bioelectroanalysis.The bibliography includes 460 references.
1. Introduction. Chemical and biological catalysts as complementary fundamentals of sustainable development
The resource, energy, and environmental problems existing to date bring about the need to develop and scale up fundamentally new methods for matter and energy conversion. The material, engineering, and ecological development of society and the growth of population require more intense industrial production and, in some cases, a conceptual change in the fundamental engineering processes that form the basis of human existence. Global problems of relationship between humans and the environment are of prime importance. The assessment of trends in science and technology and the development of the basis for strategic national planning, taking into account these trends and the existing engineering experience, appear to be of particular importance.
In order to achieve the sustainable development declared by the UN in 2015, the international industrial and economic community is making significant efforts to transform and improve the existing production processes and technologies. Large amounts of data have been accumulated, and the search for solutions that can significantly change both the current technological structure of society and the systems of product consumption and service provision is in progress.
The intensity and speed of works aimed at the development and implementation of new, more advanced technologies are fairly high. The sustainable development technologies are based on several key criteria:
— renewable or virtually infinite resources;
— improvement of the environmental quality as a result of industrial implementation of a process;
— provision of the design and scaled implementation of new efficient processes of matter conversion as a result of science and engineering development;
— understanding and analysis of processes in nature and in the human body.
Chemical processes involving enzymes most fully meet the above criteria because these biomolecules have a high catalytic potential.
Comparison of enzymes with conventional chemical catalysts under similar conditions (temperature, concentration) demonstrates obvious advantages of enzymes for acceleration of chemical reactions.[1] For example, the known comparison of enzymes with the hydrogen ion (the hydroxonium ion is the most typical chemical catalyst for hydrolysis) indicates that the ratio of the reaction rate constants may reach 1.7 × 1012͘. This means that if an enzyme-catalyzed reaction proceeds within 1 s, the same reaction in the presence of a hydrogen ion will take ~ 55 000 years.
Since the discovery of catalysis, including biocatalysis, by K.S.Kirchhoff (1812 – 1818), a Russian pharmacist and researcher, biocatalysis has attracted the attention of researchers for many decades as the main subject of biochemistry. However, in the mid-20th century, it became clear that biocatalysis could also be the basis of the most efficient chemical engineering processes. Owing to the catalytic activity, high specificity (selectivity), unique availability, and an enormous potential for the design of protein molecules, enzyme catalysis has become an object of intensive chemical and engineering studies. A fundamentally important contribution to elucidation of the nature of biocatalysis and to expansion of its practical application was made by Corresponding Member of the USSR Academy of Sciences, Ilya Vasilyevich Berezin, whose 100th anniversary of birth was celebrated in 2023. The decisive role in the further development of chemical enzymology in the USSR and then in Russia belongs to the scientific school of I.V. Berezin, Professor and Dean of the Faculty of Chemistry, Lomonosov Moscow State University. The I.V.Berezin’s scientific school formed under the influence of the famous school of chemical kinetics headed by Academician N.N.Semenov, Nobel Prize winner in Chemistry, and Academician N.M.Emanuel. I.V.Berezin’s achievements in science are well illustrated by the idea he stated: ‘Enzymes are chemical catalysts’. Before I.V.Berezin’s works, biological catalysis was considered as a complex phenomenon bearing some features of vitalism. Meanwhile, owing to the studies carried out by I.V.Berezin and his followers, it became clear that enzyme catalysis can be quite simply and reliably interpreted in terms of physical chemistry and has a huge potential for technical implementation of many chemical reactions. Data on enzyme structure and understanding of the mechanism of enzyme action provide fundamentally new prospects for medicine and ecology.
While discussing the trends in the development of chemical enzymology, one cannot but mention the factors that have had a significant impact on this field of science not only in Russia, but also all over the world. In the early stage, the attention was focused on the kinetics of enzymatic reactions and physicochemical mechanisms of enzyme catalysis, which subsequently promoted the application of enzymes in a wide range of human activities. The foundation of the Division of Chemical Enzymology at the Faculty of Chemistry of the Lomonosov Moscow State University in 1974 was an important organizational achievement. This made it possible to start training highly qualified specialists, who later became leaders of research groups in Russian and world universities and companies.[2, 3]
Quite a few editions are to be mentioned among research and methodological materials.[4-12] These books and study guides written by the ‘first circle’ of I.V.Berezin’s students and followers summarized the most advanced experience in the study and application of biocatalysis known at that time and were useful for both the professional growth of the authors and the development of educational programs at the Division of Chemical Enzymology, which became popular among chemistry students.
The international conferences on biocatalysis regularly held in Russia have also become an important step towards popularization and development of domestic works in the field of biocatalysis. The active research into the chemical mechanisms of biocatalysis in the 20th century revealed the unique properties of enzymes and provided an understanding of how they can incredibly accelerate many reactions.[13-17]
Along with numerous benefits of enzymes as catalysts, their most significant advantages over chemical catalysts were revealed, first of all, high chemo-, regio-, and stereoselectivity. Owing to appearance of immobilization methods, which enabled repeated use of enzymes that were expensive at that time, and to the accumulated fundamental knowledge about the kinetics, control, and mechanisms of biocatalytic reactions, the practical use of biocatalysis in industrial processes has markedly advanced since the 1960s. A fundamental issue that later promoted the large-scale use of enzymes in industrial production was the development of genetic engineering methods, which made it possible to express almost any enzyme using a suitable producer and accumulate the enzyme in large quantities. This made enzymes available catalysts and ultimately minimized the share of the biocatalyst in the cost of the target product. Currently, we are witnessing the active use of biocatalysis and enzymes in the production of a wide variety of products.
Other factors favourable for the use of biocatalysis should also be noted. First of all, mention should be made of the broad public and political discussion of environmental problems, which started in the 1980s and gave rise to the concepts of green chemistry, closed-loop processes, sustainable development, orientation towards renewable raw material and energy sources, and realization of the necessity of careful attitude to non-renewable resources.[18-21] Raising of these issues was followed by formulation of particular tasks, the effective solution of which is largely associated with the use of biocatalysis.[22] Solution of global problems requires application of a variety of methods, and in the wide range of available means, it is necessary to identify the areas in which the use of biocatalysis appears most promising. One hot spot for the practical application of the catalytic advantages of enzymes may be identified in terms of the E-factor (environmental factor reflecting the presence of pollutants) in the characteristics of wastes produced in various fields of industrial chemistry [23] (Table 1). The need to reduce the amount of waste has become a key issue in the development of the green chemistry concept.
Enzymes are capable of performing chemical transformations at high rates and in high yields; however, it is necessary to find or create an enzyme catalyst that would have the required specificity and would be stable under the reaction conditions. Out of thousands of enzymes that perform the chemical reactions in living systems, only a few hundred are currently in use. This shows that the potential of biocatalysis in industry has not yet been sufficiently implemented.
Which of the set goals can be considered to be of the first priority? One such goal is active use of biocatalysis in fine organic synthesis and pharmaceutical industry (see Table 1). Analysis of the experience of large pharmaceutical companies in the synthesis [24, 25] and a relevant discussion [26] identified the following key problems of pharmaceutical industry that can be addressed using biocatalysis:
— the need to develop efficient methods for amide bond formation,
— decrease in the consumption of organic solvents, which make the largest contribution (up to 80%) to waste production,
— increase in the chemoselectivity of reactions,
— inadmissibility of genotoxic pollution in the final product (reduction of the number of catalysts based on heavy metal complexes).
Great prospects are also associated with implementation of distinctive features of enzyme catalysts such as chemo- and regioselectivity, which may eliminate the protection and deprotection steps in chemical synthesis and, due to decrease in the number of steps, may significantly increase the economic feasibility of the synthesis.
Apart from the chemo-, regio-, and stereoselectivity, biocatalysis can ensure mild reaction conditions, a simpler set of reactants, and less expensive and safer equipment design for the industrial process, because effective enzymatic reactions do not require high pressure or other drastic conditions (low or high pH or temperature) as well as explosion- and fire-hazardous organic solvents, since enzymatic reactions preferably proceed in aqueous solutions. This does not rule out the use of enzymes in organic solvents,[27] which attests to the possibility of complex processes that would combine the potential of biological and chemical catalysis. This idea is actively pursued in recent years.[28-30]
The enzyme catalysis techniques and the conventional chemical catalysts are being developed in parallel and are complementary to each other. Comparison of chemical and biological catalysts has been made many times in various reviews and continues today in view of the dominance of certain trends in the development of the world economy and particular branches of economy. In the petroleum industry, processing of plastics, waste pyrolysis, Fischer – Tropsch synthesis, and other processes requiring high temperatures and pressures, inorganic catalysts are commonly obvious leaders. However, enzymes as basic biological catalysts are superior for processes that require low capital cost, highly specific action, enantioselectivity, high activity at low and moderate temperatures, and the highest possible yields of target compounds in catalytic reactions along with minimized amount of by-products.
Currently, enzymes (mainly hydrolases such as proteases, carbohydrases, lipases, polymerases, and nucleases) [31, 32] are superior to almost any chemical catalyst and are used as components of low-temperature laundry detergents and feed supplements, in agriculture, in medicine for the treatment of various enzymatic disorders, in genetic analysis and diagnosis, and in the food industry (Table 2).
Enzymes play an important role in the textile and pulp-and-paper industries and as components of biosensors. A classic example is glucose oxidase, which is widely used to monitor the blood glucose level.[40] The possibility of genetic modification of enzymes markedly expands their catalytic potential in relation to substrates, reaction temperature, and pH value.
In 2022, the cost of biocatalyst production was 25% of the total production cost of all catalysts in the world.[41] In the next 10 years, the role of enzymes in the global economy, medicine, and ecology is expected to considerably increase.
Chemical and biological catalysis as the base of biotechnology forms the ground for modern methods of conversion of matter in a technology-based society. Large-scale production of enzymes for the needs of food industry, textile industry, and agriculture is an integral part of basic technological processes. Since microbiological industry is based on the knowledge of enzymes and methods for the control of enzyme expression, the practical significance of enzyme catalysis becomes obvious. There are known limitations on the industrial implementation of processes using protein catalysis:
— many practically important processes require high temperatures to meet the proper thermodynamic conditions; meanwhile, enzymes can operate at temperatures up to 90°C;
— enzymes are homogeneous catalysts and are used, in most cases, as expendable reagents if this is economically justified; although this problem can be solved by immobilization of enzymes on inorganic or polymeric supports, this procedure requires additional process stages and economic costs;
— the use of enzymes in large-scale production processes is often restricted by their relatively low stability on long-term operation; quite a few studies are aimed at increasing the stability of protein molecules through genetic modifications and protein engineering (see below);
— the industrial use of enzymes is complicated, in some cases, by their outstanding specificity and selectivity to the substrate (reactant); however, the unique capabilities of modern genetic engineering make it possible to modify the enzyme active sites and tune the active site towards new compounds (see below).
Since the general trend of development of chemical engineering processes is, to some extent, directed towards the use of natural organic resources (biofuels, biopolymers, biopharmaceuticals, etc.), the modern studies of enzymes fit well into this trend.
This review is devoted to analysis of the most important trends in the development of chemical and engineering enzymology, the outstanding results and promising applications of enzymes as catalysts, although detailed consideration of many industrial aspects of biocatalysis are beyond the scope of the review. The attention is concentrated on modern achievements in the physicochemical fundamentals of the molecular processes in enzyme active sites, the use of genetic engineering methods as a protein strategy to create enzymes with new properties, the role of enzymatic processes in molecular medicine, and development of new methods for analysis and diagnosis.
2. Supercomputing technologies and bioinformatics as a fundamental breakthrough in the understanding of molecular mechanisms of enzyme action
The accumulation of large amounts of information on amino acid sequences and protein structures in public databases and development of supercomputers made it possible to perform the bioinformatic analysis of large protein superfamilies [42] (Fig. 1). Hence, it became possible to identify the amino acid residues most important for the functioning of enzymes, reveal previously unknown binding sites for regulatory ligands,[43] and establish the relationships between various binding sites and the active site of the enzyme.[44] The use of bioinformatic and molecular modelling techniques provided a qualitatively new level in the study of the mechanism of enzyme action and structural organization of active sites.[45] For example, it was shown that hydrolases can be subdivided into four groups according to the type of active site organization and catalytic cycles, differing in the mechanism of water activation. The important role of Gly, Pro, and Cys residues in the structural organization of protein molecules and their active sites was established.[46]
![[{"id":"Amz9zSlzZx","type":"paragraph","data":{"text":" Generalized strategy of bioinformatic approaches to study enzymes, in particular using supercomputers. There is spiral progression from simple to complex: from the primary amino acid (or nucleotide) sequence to a mature three-dimensional structure of the enzyme and then to the mechanism of its action; each subsequent level requires a higher amount of resources and gives more interesting results for science and practice."}}]](/storage/images/resized/NZraTxVqPi68u5HKMBTALueoW4CSaCzbZeoeBuvl_xl.webp)
Bioinformatic analysis is used to identify amino acid residues of two functional types: those in conserved positions of enzyme superfamily that directly participate in the catalytic mechanism and those in specific positions that are responsible for the functional diversity of superfamilies.[47] The subfamily-specific positions are identified using a scoring function based on genomic and structural information.[46-49] An important feature of this analysis is that it is applicable not only to thoroughly characterized proteins, but also to little studied enzymes for which only the primary amino acid sequence is known.
The specificity and conservation of amino acid residues in structural cavities of enzymes serve as a criterion for evaluation of the functional significance of binding sites and can be used to identify and classify them.[50] The identification of the subfamily-specific positions (which are conserved within enzyme subfamilies of bacteria or mammals, but differ between subfamilies) helps to find the structural difference between the binding sites in the homologous enzymes of pathogenic bacteria and humans and between the involvements of the amino acid residues in the interaction with ligands.[50, 51] There are seven web servers for implementation of the above approaches, which are listed below (the web addresses are indicated in parentheses):
— Mustguseal (https://biokinet.belozersky.msu.ru/mustguseal);
— Zebra2 (https://biokinet.belozersky.msu.ru/zebra2);
— Zebra3d (https://biokinet.belozersky.msu.ru/zebra3d);
— pocketZebra (https://biokinet.belozersky.msu.ru/pocketzebra);
— visualCMAT (https://biokinet.belozersky.msu.ru/visualcmat);
— vsFilt (https://biokinet.belozersky.msu.ru/vsfilt);
— Yosshi (https://biokinet.belozersky.msu.ru/yosshi).
The key web server Mustguseal can automatically construct alignments for large protein superfamilies using data on the structure and sequences contained in public databases; a supercomputer protocol has been developed for high-throughput analysis of large data arrays. This web server possesses functions that are absent in the known world analogues and can not only align but also select structurally and functionally diverse related proteins from public databases and to construct large alignments of protein superfamilies involving thousands of structures and sequences of homologues. This is attained by using search algorithms based on structural similarity, in order to reveal evolutionarily distant proteins, to perform structural alignment, and to perform further similarity-based search for amino acid sequences for identification of evolutionarily related proteins in the families and subsequent alignment of amino acid sequences. These structure-based alignments using the developed approach can be performed in the automated online mode.
The related web servers Zebra2 and pocketZebra are able to analyze the obtained sequences in order to identify the conserved and specific positions in the superfamily, find unknown binding sites in the proteins (enzymes), determine their importance for functional properties, and identify distinctive features in a particular representative of the family. The visualCMAT web server can be used to reveal the relationship between different sites in the protein structure and to elucidate the network of interacting amino acid residues.[44]
The Zebra3d web server finds specific 3D patterns in the protein superfamily that represent structural elements important for the enzyme action mechanism and are responsible for the difference of properties (such as substrate specificity, catalytic activity) between enzymes that belong to different functional subfamilies and between conformers of one enzyme, owing to the known spatial orientation of the key amino acid residues and parts of the backbone. The specific 3D patterns can be used for functional annotation and rational design of proteins.[52] Determination of 3D motifs qualitatively supplements the information about specific and correlated positions in enzyme subfamily and expands the scope of protein design methods, e.g., by inserting 3D motifs of disulfide bridges into protein structures in order to generate biomolecules with altered functional properties (Yosshi web server).[53]
The vsFilt web server is able to take into account the specific interactions between the protein target and a functional modulator while selecting the most promising compounds as drug prototypes.[54] The bioinformatic analysis of families of homologous enzymes identifies the differences between the active site structures and use the results to design selective inhibitors, for example, by means of the vsFilt structural filtration algorithm [54] during virtual screening.
The data gained by bioinformatic analysis described above have been used to propose new ways to address some scientific and practical problems: new methods for regulating enzyme activity were substantiated, a search for selective inhibitors of pathogen enzymes was carried out, the amino acid substitutions for enzyme bioengineering were determined in order to deliberately change the functional properties of enzymes.[55, 56] The experience of application of bioinformatic techniques showed that they are efficient for studying the mechanism of action and for engineering of various enzymes.[57-61]
A methodology for the search for new type of enzyme modulators proposed in recent years is based on identification of previously unknown binding sites other than the active site. Analysis indicates that proteins have numerous potential ligand binding sites the function of which is unknown. The functional significance of these sites might be indicated by the presence of specific or conserved amino acid residues, which are determined via bioinformatic analysis of protein superfamilies.[43, 62] The computational platform based on the Mustguseal web server is able to find such binding sites and identify complementary ligands, taking into account differences in the structural organization of the sites for pathogen, human, and animal enzymes.
The understanding of characteristic features and distinctions in the active site and other binding site structures in enzymes from various sources is important not only for the creation of selective inhibitors, but also for determining the influence of components of the reaction mixture on the efficiency of biocatalytic processes and for the search for enzymes with a desired specificity. The corresponding computer design procedure was tested by the search for bifunctional inhibitors of influenza virus neuraminidase,[63, 64] neuraminidase A from Streptococcus pneumoniae,[65] transketolase, glyceraldehyde 3-phosphate dehydrogenase, and L,D-transpeptidase-2 from Mycobacterium tuberculosis.[66-69] This procedure identifies selective inhibitors that are effective against pathogens but safe for humans. Apart from computer screening, which precedes and accelerates the drug development, molecular modelling techniques are also actively used in drug design.[16, 17, 50, 51] The introduction of bioinformatics and molecular modelling makes it possible to significantly accelerate the development of new drugs, including those with a fundamentally different mechanism of action.
The bioinformatic analysis of enzyme superfamilies and relevant web servers can also be used to identify the range of mutations in the key human proteins (enzymes) that are associated with a pathological condition. This may result in the creation of a unified database of human proteins (enzymes) that would list the pathological mutations; this may enable the development of a personalized medicine information service and an automated service based on the patient’s DNA sequencing data.
The fundamental causes for the high rate of action of protein catalysts are the subject of modern physical chemistry.[1] Revolutionary opportunities for the development of this research area are provided by supercomputer technologies,[70] which can trace the structural and kinetic changes in the protein molecule throughout the catalytic cycle on the basis of fundamental equations of quantum mechanics and methods of quantum chemistry.[71, 72]
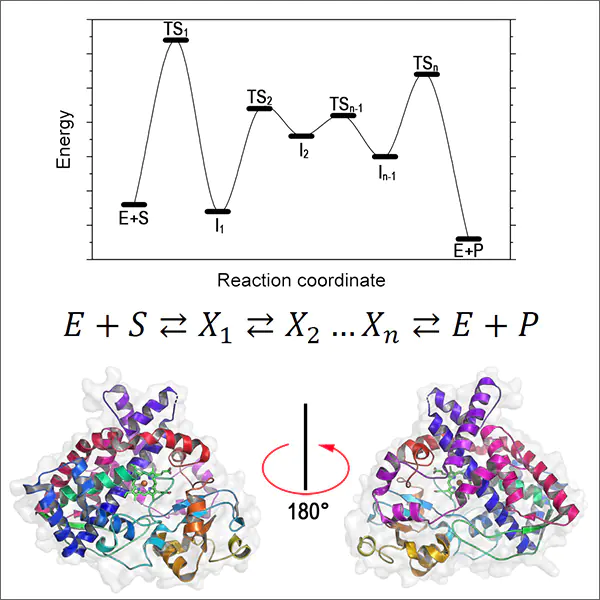
Molecular modelling has provided tools for elucidation of enzymatic reaction mechanisms, identification of metastable intermediates, and determination of transition state structures. The possibility of constructing the free energy change profile for transition from the reactant to the reaction product and identifying the extrema in the energy pathway proved to be highly important. Using this profile, it is possible to estimate the rate constants of all elementary steps of the catalytic cycle. Meanwhile, due to the instability of intermediates formed at high rates, identification of their structures and interconversion rates by modern experimental methods is virtually impossible. The supercomputer simulation opens up the way for solving this ‘unsolvable’ problem.[73-79]
The following fundamental features of enzyme catalysis were clearly identified as a result of supercomputer simulation:
(1) all enzymatic reactions within the catalytic cycle of reactant transformation into products consist of numerous steps, including the formation of stable and unstable intermediates. The lifetimes of the intermediates are in the range of nano(micro, milli)seconds. Classic examples of enzymes that catalyze multistep reactions are serine hydrolases, ribonucleases, and aminotransferases. Modern molecular modelling techniques using high-performance computing through analysis of reaction mechanisms can identify all metastable intermediates;[76-79]
(2) the catalytic cycle of enzymatic transformations is implemented within a conformationally flexible polymer matrix and involves functional groups that are identified as active site components. The structural and functional modelling of catalytic cycles by quantum mechanics/molecular mechanics (QM/MM) methods illustrates the important role of conformational changes in the active site during catalytic reactions. The conformational changes are determined by the structure and steric features of the active site and ensure positioning and migration of reactive groups into the required points of activation of particular bonds in the reactant or intermediate molecule.[80-82] In a certain approximation, these changes during the catalytic cycle can be described as operation of a ‘molecular machine’ forming a sequence of necessary catalytic steps;
(3) numerous mechanisms of enzymatic reactions were analyzed by supercomputer simulation methods, e.g., the following reactions:
— synthesis of N-acetylaspartic acid in the presence of aspartate N-acetyltransferase encoded by the NAT8L gene;[83-85]
— hydrolysis of the neuropeptide N-acetylaspartylglutamate, which plays an essential role in the functioning of glutamate synapses and mechanisms of acquiring and retrieving information that determine memory,[86] catalyzed by glutamate carboxypeptidase II;[74, 75, 80-82]
— N-acetylaspartate hydrolysis with aspartoacylase, which is a key enzyme of neurovascular coupling participating in human brain metabolism in response to an external excitation signal.[69, 87, 88]
Owing to the development of graphics accelerators and implementation of quantum chemistry software packages in them, it became possible to perform molecular dynamic calculations with QM/MM potentials. This substantially expanded the views on the mechanisms of enzymatic reactions and made it possible to consider the reaction pathways in hydrolases from the dynamic behaviour of enzyme – substrate complexes.[63-65] Criteria were proposed for identification of electrophilic atoms in organic molecules containing carbonyl groups on the basis of analysis of three-dimensional electron density maps. The applicability of these procedures to analysis of various structures in enzyme – substrate complexes was demonstrated by Khrenova and co-workers.[89-92] It was shown that QM/MM-based molecular modelling provides correct interpretation of experimental data,[92] reveals the most probable chemical reaction mechanism, and gives explanation for the diversity of data that were obtained for a set of related systems, in particular enzymes, containing amino acid substitutions.[91] The use of molecular modelling methods promotes the development of new enzyme inhibitors and elucidation of the mechanisms of their action.
3. Post-genomic era: new technologies for search and creation of biocatalysts
Enzymes are unique highly specific catalysts. However, very often, this feature proves to be also a drawback, since during evolution, Nature optimized the enzyme specificity to natural substrates; however, many target compounds differ in their structure from natural molecules. As an example, consider penicillin acylase, which is fairly effective in the synthesis of ampicillin (Amp) and several times less active in the synthesis of amoxicillin, although the latter markedly surpasses Amp in the antibacterial properties and differ from Amp only by an additional hydroxyl group in the para-position of the benzene ring in D-phenylglycine. Particularly the enzyme specificity, together with relatively low stability and high cost of preparation from natural sources, substantially restricted the practical implementation of biocatalytic processes. In addition, the optimal conditions for enzyme functioning in the cell (e.g., pH required for enzyme activity) often differed from the optimal process parameters for the synthesis of the target product. As a result, conditions of the real process were a trade-off between the optimal conditions for functioning of the biocatalyst and for the chemical reaction. One more exceptionally important factor that affected the design and development of new biocatalytic processes was the absence of an enzyme with the required activity, with the known methods for the search for new biocatalysts being extensive and having a poorly predictable outcome. In addition, in most cases, microorganisms were used in practice as enzyme sources. However, it is well known that more than 99.9999% of microorganisms existing in nature cannot be obtained in a pure state in laboratory.
The situation started to change fundamentally (and the progress still continues) in the late 1980s to the early 1990s when the scientific community entered the so-called post-genomic era. In this period, new methods and approaches started to be used as research tools in life sciences.[93] Suffice it to mention here the Nobel Prizes in chemistry awarded for DNA sequencing (1980), development of various sorts of polymerase chain reaction (PCR) (1994), and development of methods and approaches of genetic engineering and protein design (2018). The methods such as X-ray diffraction analysis, electron microscopy, nuclear magnetic resonance, computer simulation, etc. gained completely new content and development. The term ‘post-genomic era’ should be conceived as not only technological progress in sequencing of various genomes, ranging from archaea or bacteria to humans, although this information is exceptionally important and useful, but also, for example, advances in the diagnosis of various hereditary diseases, discovery of new metabolic pathways and enzymes they involve, analysis of mechanisms of drug resistance, etc.
Modern high-throughput sequencing methods allow determination of DNA sequences in a sample and subsequent assembly of the resulting sequences into separate genomes. As a result, the problem of uncultivated organisms was quickly solved, and for enzymologists, the choice of potential enzymes immediately increased by millions of times. The sequencing of hundreds of thousands (and even millions) of genomes brought about the transition from quantity to quality. This gave rise to a giant information space; hence, appropriate bioinformatic methods and supercomputers were required to handle it. Data on the sequences and properties of known enzymes were combined into specialized databases, the use of which sharply narrows down the search for enzymes with specific properties. The large-scale analysis of amino acid sequences in proteins and enzymes is described in sufficient detail in the previous Section of the review, but the results of this analysis should be treated with great caution, as indicated by numerous errors in the annotation of new genomes both in the number of genes of a particular enzyme and in the functionality (as an example, see Section 3.1). The same is true for structural modelling. The errors are due to the fact that the calculation error is ± 1 kcal mol–1, and, hence, the maximum and minimum protein – ligand interaction constants in the docking would differ by a factor of 50. For this reason, expert evaluation still plays a crucial role in the preliminary selection of enzyme candidates.
Nevertheless, the above-described methods are usually utilized in the initial stage of biocatalyst design tailored for a particular process. As a result, the ideology of development of new biocatalytic processes has completely changed. First, the optimal process conditions are selected; then the parent enzyme is chosen; and protein engineering techniques are applied to adjust the properties of the enzyme to the requirements of the process. Moreover, the biocatalyst itself can be changed. For example, reactions using α-D-amino acid ester hydrolase (HAA), instead of penicillin acylase (PA), are currently being developed for the preparation of aminopenicillins and aminocephalosporins. Higher efficiency of HAA is due to the fact that the acyl-containing enzyme is obtained from the methyl ester rather than from the much less reactive amide, as in the case of PA. In addition, since HAA is an esterase, hydrolysis of the final product (amide) with this enzyme proceeds much more slowly than that with PA, which is amidase. Consequentky, the yield of the final product is often much higher in the presence of HAA than with PA.
The post-genomic era is also characterized by the appearance of new biocatalytic processes. As an example, consider the CRISPR/Cas system for genome editing (Nobel Prize in Chemistry 2020). Currently, there are a few variants of this system, and new versions are being proposed, while the problem of its practical implementation refers to the ethical and legislative sphere.
Due to the restricted size of the review, below we consider the production of only classic biocatalysts. Tishkov et al.[94] addressed a variety of practically important enzymes; depending on the purpose, enzymes of the same type were obtained from different sources according to reported procedures (see examples below). As examples, we chose two enzymes, formate dehydrogenase (FDH) and D-amino acid oxidase (DAAO), because these biocatalysts represent two extreme cases of enzymes with high and very low homology. The milestones of this study are considered below.
3.1. Choice of the parent enzyme
The choice of enzyme is one of the most complicated issues. The differences between the properties of the same enzyme, but isolated from different sources, can be readily assessed by forming a reduced nicotinamidine adenine dinucleotide phosphate (NADPH) regeneration system based on formate dehydrogenase (EC 1.2.12) (Fig. 2). The FDH-catalyzed reaction in the general form in depicted in Scheme 1.
![[{"id":"w1VjwE7lEl","type":"paragraph","data":{"text":"Structures of FDH dimer from <i>Pseudomonas</i> sp.101 (<i>a</i>) and monomeric subunits of enzymes from <i>Candida boidinii </i>(<i>b</i>) and <i>Arabidopsis thaliana</i> (<i>c</i>). The structural parameters were retrieved from RCSB PDB (codes 2GUG, 8HTY, and 3NAQ, respectively) and are represented using the PyMOL program (version 1.7.6, Schrödinger, LLC)"}}]](/storage/images/resized/ARKbGO9wn1xFlcO1LzygCfpPRqn6AJgtJaMgzccm_xl.webp)

The specificity of dehydrogenases to NAD+/NADP+ is quantitatively expressed as coenzyme preference (CP) determined by formula (1) [68]

where kcat is the catalytic constant, KM is the Michaelis constant.
It was found that FDH from the bacterium Pseudomonas sp.101 (PseFDH) is characterized by CP of 2400, while the same enzyme from the yeast Candida methylica and C. boidinii (CboFDH) have CP of 250 000. It may seem that a 100-fold difference between CPs for bacterial and yeast enzymes is not high. However, in the case of PseFDH, the obtained mutants had a catalytic efficiency (kcat /KM) and specific activity for NADP+ equal to those for wild-type PseFDH for NAD+. In addition, the above values of the best yeast FDH mutants for NADP+ were 5 – 10 times lower.[95] While choosing the parent enzyme, one should also take into account characteristics that determine the production cost and application conditions. For the considered example, stability to the action of proteases is important, because the inactivation by protease impurity is one of the main reasons for the loss of activity during enzyme storage. The PseFDH enzyme is exceptionally stable to proteases; therefore, it can be stored at +4°C. The oxidation or modification of the SH groups of Cys residues also leads to enzyme inactivation. In the case of PseFDH, the mutants resulting from the replacement of two Cys residues did not lose activity for more than 10 years when stored in a phosphate buffer at +4°C, whereas CboFDH in which two Cys residues have been replaced should still be stored at –20°C in 50% glycerol.[96]
Thus, the choice of the initial enzyme is highly important and can be performed using two main approaches.
1. Genome mining. The search for potential D-amino acid oxidases (DAAO) (Fig. 3) catalyzing the amino acid oxidation (Scheme 2) was performed in the thermotolerant yeast Ogataea parapolymorpha DL-1 (OpaDAAO).[97, 98]
![[{"id":"V8vYW3ClMC","type":"paragraph","data":{"text":" Structures of D-amino acid oxidase (<i>a</i>), D-aspartate oxidase from <i>O. parapolymorpha</i> (<i>b</i>), and human D-aspartate oxidase (<i>c</i>). The structural parameters were retrieved from the UniProt (W1QLN4 and W1Q8E7) and RCSB PDB (6RKF) data bases, respectively."}}]](/storage/images/resized/NqygJI0v5z5myxq6NDd0elMujjts5VHUb5gLIIGk_xl.webp)

The genome of this yeast was sequenced in 2013, and genome annotation revealed only two genes of potential DAAO, which had errors. Classic DAAO with a broad range of substrate specificity was annotated as specific D-aspartate oxidase (DASPO), while DASPO was interpreted as DAAO. Thorough analysis revealed five DAAO genes and one DASPO gene in the genome of O. parapolymorpha DL-1. It is noteworthy that formerly, it was considered [97] that only one DAAO and one DASPO gene should be present in yeast genomes. The six genes were cloned and expressed in Escherichia coli cells. All enzymes turned out to be oxidases and differed in the substrate specificity and pH activity profile. Four DAAOs had no analogues in the literature. Analysis of the catalytic properties showed that various OpaDAAOs were superior in activity to previously described DAAOs and DASPOs from other sources.[98] Three-dimensional structures were determined for two OpaDAAOs. This gave a base with established structure – function relationships, which was used in the studies according to the second approach.
2. Genome screening. In this case, the labour intensity and the overall success of the work are determined by the degree of conservation of the primary structure. For example, in the case of FDH, the search for these enzymes in various genomes is quite simple, since the homology is > 50% even between distant organisms.[96] Formate dehydrogenase from Staphylococcus aureus (SauFDH) with a homology of only 40% was an exception.[96] According to evolutionary analysis, SauFDH belongs to a separate branch of evolution. The SauFDH gene encoding the FDH synthesis was cloned and expressed. The specific activity of this enzyme was found to be 2.5 times higher than that of other described formate dehydrogenases.[99]
In the case of DAAO, the homology level is not more than 30 – 35%.[100] Therefore, for reliable identification of genes of potential DAAOs in the genomes of extremophile bacteria and archaea, one more stage of enzyme selection was added, that is, simulation of 3D structures and their comparison with experimental and model structures of known DAAOs and glycine oxidases. As a result, ten DAAOs were found in bacteria and one enzyme was found for the first time in archaeal cells. Analysis of the active site structure for DAAO from the bacterium Natronosporangium hydrolyticum ACPA39 (NhyDAAO) suggested that this enzyme could be highly specific to D-Phe (used to diagnose gestational diabetes in pregnant women); this was confirmed after NhyDAAO was cloned and expressed in E. coli cells.[101]
Analysis of the model active site structure of DAAO from the archaea Natrarchaeobius halalkaliphilus AArcht4 (NhaDAAO) showed that this enzyme can oxidize not only usual D-amino acids but also their N-substituted analogues. The produced recombinant NhaDAAO was found to actually exhibit this unusual specificity. Catalysis of the oxidation of mono- and trimethylated Gly (sarcosine and betaine, respectively) is of particular interest. The oxidation of betaine with enzymes has not been described in the literature.
3.2. Bioengineering of enzymes
The selected enzyme is optimized using both random mutagenesis (RM) and rational design methods. RM was most popular from the mid-1980s to the late 1990, but now rational design plays a major role in protein engineering, because it is much more efficient and cost effective. The studies are carried out along several lines: improvement of catalytic properties, creation of enzymes with new properties, and increase in the temperature and operational stability.
Protein engineering experiments were carried out with various enzymes such as FDH,[102] DAAO,[103] peroxidase (PO),[104] penicillin acylase (PA),[105] α-D-amino acid ester hydrolase,[106] phenylacetone monooxygenase,[107] and so on. The FDH [76] and DAAO mutants,[103] in which 5 – 7 substitutions resulted in enhanced catalytic properties and higher thermal and chemical stability, proved to be most interesting. Immobilized FDH and DAAO retained the activity at 80 and 90°C. The mutant peroxidase had an increased electron transfer efficiency within the protein globule.[104] The results of engineering of FDH from the yeast O. parapolymorpha DL-1 were unexpected. During cloning, the Gly or Ala residue was added to the N-terminus of the enzyme.[108] The Gly residue did not affect the properties of OpaFDH, while the addition of Ala induced a four-fold increase in the enzyme thermal stability.[108] The latest achievements and current trends of protein engineering can be found in the literature.[109]
3.3. Enzyme-based hybrid biocatalysts
The approach that implies combining two or more enzymes into one polypeptide chain (creation of fusion proteins) proved to be efficient. Two types of hybrid biocatalysts were obtained: FDH with cytochrome P450 BM3 monooxygenase [110] or phenylacetone monooxygenase.[111] In the case of the FDH-P450 fusion construct, the efficiency of conversion of various substrates was 6- to 60-fold higher than that attained with a mixture of single enzymes.[110]
Thus, advances in bioinformatics, sequencing, and structural biology enabled the selection and engineering of effective enzymes for many areas of science and technology. A mere listing of recently developed processes involving biocatalysts would have taken several pages. To confirm the significant role of enzymes in the development and progress of modern technologies, it is sufficent to mention that enzymes are used as components of washing detergents and food supplements in agriculture (see also Section 1). Regarding the production output and cost, these two application areas alone account for more than a half of the market of enzyme products (see https://www.gminsights.com/industry-analysis/enzymes-market), which exceeded 20 billion dollars per year in 2022, according to various estimates. One more vivid example of application of enzyme engineering in modern technologies is the production of the Saphir Bst2.0 Turbo DNA polymerase mutant for the diagnosis of coronavirus SARS Cov-2 by isothermal polymerase chain reaction performed by Jena Bioscience within the shortest time possible (see https://www.jenabioscience.com/molecular-biology/isothermal-amplification-lamp/polymerases/pcr-390-saphir-bst-turbo-polymerase). Currently, these technologies are widely used to produce highly stable and active FDH and develop effective FDH-based biocatalysts for atmospheric CO2 fixation.[94]
4. Protein engineering and post-translational modifications for the production of enzymes with new properties
4.1. Luciferases: enzymes that produce light quanta
One of the natural bioluminescent systems (Fig. 4, Scheme 3 and Scheme 4) is the luciferin–luciferase system of the Luciola fireflies (see Fig. 4a). The bioluminescence (emission of visible light in the 400 – 700 nm wavelength range) occurs during the oxidation of organic substrate (luciferin) catalyzed by the luciferase enzyme (EC 1.13.12.7).. In the enzyme molecule, two domains (large N-terminal domain and small C-terminal domain) are connected by a mobile non-structured polypeptide loop. Particularly the dynamic structure of the protein plays an important role in the function of firefly luciferase,[112] which can assume three different conformations: open conformation (in the absence of substrates) and two closed catalytic conformations corresponding to single reaction steps (adenylation and oxidation) (Scheme 3, see also Fig. 4).
![[{"id":"_k5oy0sF2N","type":"paragraph","data":{"text":"Structures of luciferase (Luc) from firefly <i>Luciola mingrelica</i> (<i>a</i>), bacterium <i>Photobacterium leiognathi</i> (<i>b</i>), and fungus <i>Armillaria mellea</i> (<i>c</i>). The structural parameters were retrieved from the RCSB PDB (codes 2D1R and 6FRI) and UniProt (A0A3G9JTR4) databases, respectively."}}]](/storage/images/resized/yzU2Bjd9FUwCj6eXjG5iLsZ9Rx0LmkUIHbXkDJDm_xl.webp)
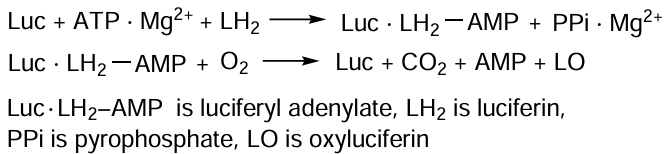
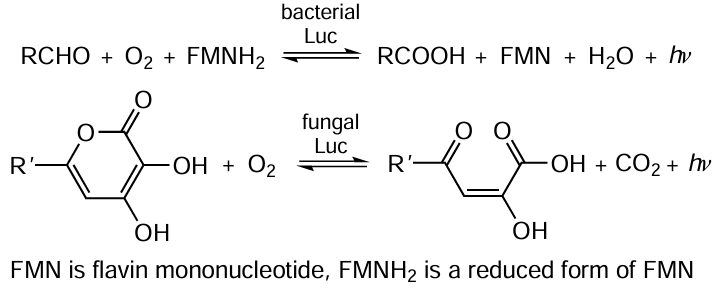
Upon binding of substrates, luciferin and adenosine triphosphate (ATP) (see Scheme 3), the free conformation of Luc is transformed into the adenylating conformation: the domains approach each other and are rotated through 90° relative to the orientation in the free conformation.[113, 114]
Luciferin adenylation results in the formation of luciferyl adenylate, which is anhydride of a carboxylic and phosphoric acids. Unlike luciferin, it is highly reactive in the oxidation. The catalytically important C-domain residues (Lys529 and Thr527) are incorporated into the enzyme active site and promote the formation of luciferyl adenylate. In the oxidative conformation, C-domain is rotated around the N-domain by ~ 140°, and a part of the C-domain, Lys443 residue, enters the active site. The oxidative conformation is very unstable and is needed only to catalyze the oxidation of luciferyl adenylate. When light is emitted, the enzyme returns to the adenylating conformation.[114] Owing to the dynamic structure of the protein, an active site configuration optimal for each step is implemented.
An important function of the Luc protein globule is the influence on bioluminescence spectra. The product of enzymatic reaction, oxyluciferin, can exist in solutions at various pH as six different species [112, 113] (Fig. 5). Phenol forms I – III exist in non-polar solvents or at a very low pH; their fluorescence maximum (λmax) occurs in the electronic spectrum at 450 nm. This blue luminescence was not observed for Luc. Phenolate forms IV–VI exhibit yellow-green (λmax = 550 – 570 nm) or red (λmax = ~ 620 nm) fluorescence, which is typical of the bioluminescence of this enzyme.
![[{"id":"ms6tpVKbKs","type":"paragraph","data":{"text":"Structures of oxyluciferin forms: <b>I – III</b> are phenol; <b>IV–VI</b> are phenolate; <b>I, IV</b> are enolate; <b>II, V</b> are enol; and <b>III, VI</b> are ketone forms. The values in parentheses are emission wavelengths. The Figure was created by the authors using published data.[[ type=\"anchor\" referenceId=\"15656\" ]] "}}]](/storage/images/resized/cQUBzN1c4XgC4cvtfbPfCQVZCaMyYBHK0I5S7i4z_xl.webp)
Studies of steady-state and subnanosecond time-resolved fluorescence of oxyluciferin and its structural analogues showed that bioluminescence in the firefly luciferin – luciferase system is generated by various tautomeric forms of electronically excited oxyluciferin, which are formed in the luciferase active site.[112, 115] The main factor determining the bioluminescence colour is the microenvironment of the emitter, which is located in the enzyme active site, where only one electronically excited product molecule is formed.[116]
Particularly the emitter molecule is a bioluminescent probe, which characterizes the state of its microenvironment at the instant of light emission.[112] A superposition of two or three forms of the emitters (E1 – E3) detected in the bioluminescence spectra attests to the coexistence of various Luc conformers in a dynamic equilibrium in the reaction mixture. Each Luc conformer contains only one type of the emitter forms indicated in Fig. 5: ketone, enol, or enolate in Eqn (2), respectively.
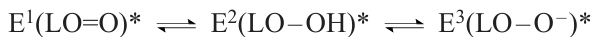
By analysis of bioluminescence spectra, it is possible to qualitatively and quantitatively identify various enzyme conformers and trace the variation of their concentrations upon the change in the external conditions or luciferase mutations. For example, after a single substitution (Tyr35Asn or Tyr35His), the bioluminescence spectrum no longer depends on pH.[117, 118] The Tyr35 residue adjoins loop 233 – 237, the position of which is important to maintain the closed conformation of the luciferase active site needed for green bioluminescence to occur.
When the bulky aromatic residue Tyr35 is replaced by smaller Asn or His, the close packing near position 35 becomes more stable, and loop 233 – 237 is retained even at lower pH; hence, the closed conformation is not disrupted.[117] Conversely, the His433Tyr mutation induces a shift of the bioluminescence λmax at pH 7.8 (pH optimum of enzyme activity) from 566 to 606 nm, which is attributable to changes in the relative contents of various forms of the emitter.[118]
The His433 residue is located in the mobile loop formed by the Tyr427 – Phe435 amino acid sequence, which connects the N- and C-domains of Luc. This loop can be considered as a hinge linking the two luciferase domains. A temperature rise can also lead to increasing amplitude of the thermal vibrations of domains relative to each other and to increasing concentration of the conformer that generates red emission. It was shown for the luciferase of Luciola mingrelica and for some single mutants at Glu457 that the fraction of the red emitter at 42°C increases to 90% for native luciferase and to 100% for mutants.[116]
Directed evolution was used to obtain a mutant L. mingrelica firefly luciferase with eight amino acid substitutions (Ser118Cys, Cys146Ser, Lys156Arg, Arg211Leu, Thr213Ser, Ala217Val, Glu356Lys, and Ser364Cys), the thermal stability of which increased by a factor of 66 at 42°C (Fig. 6).[113, 119] The catalytic properties of the mutant were considerably enhanced compared to those of many native and other known mutants of this enzyme.
The Luc protein engineering design made it possible to develop a highly sensitive quantitative method for ATP analysis and a live cell detection method. Practical aspects of using this luciferase mutant for bioluminescent ATP assay, which is widely applied in many fields of science, industry, and medicine, are presented in detail in a review.[120]
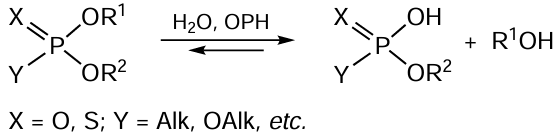
4.2. Organophosphate hydrolases: enzymes that degrade neurotoxins
Organophosphate hydrolase (OPH, EC 3.1.8.1) (Fig. 7), which exists in nature as a homodimer, attracts considerable attention for both theory and practice, owing to its catalytic characteristics, which are manifested in the hydrolysis of various organophosphorus compounds (OPC),[121-124] mycotoxins,[125, 126] and bacterial quorum sensing molecules (Scheme 5).[127, 128]
![[{"id":"hnfak_aglf","type":"paragraph","data":{"text":" Structures of the organophosphate hydrolase dimer from <i>Brevundimonas diminuta </i>(<i>a</i>) and monomeric enzyme subunits from <i>Agrobacterium radiobacter</i> (<i>b</i>) and <i>Mycobacterium tuberculosis</i> (<i>c</i>). The structural parameters were retrieved from RCSB PDB (codes 1QW7, 2D2G, and 4IF2, respectively). The catalytically important Co<sup>2+</sup> and Zn<sup>2+</sup> ions in the enzyme active sites are shown as pink spheres."}}]](/storage/images/resized/jfRoWwh0zOF20oPD0tUhA2gMKG1sgrQpwJEAevfd_xl.webp)
This enzyme proved to be efficient as a component of antidotes used in experiments with various animals [129-131] and as parts of antimicrobial compositions [132-134] tested on various microbial cells. The initial phase of investigation on this enzyme was focused on enhancement of its catalytic properties;[133] later, genetic modification of the enzyme was performed to simplify the isolation and purification procedures and thus to provide for active commercial use of OPH.
For this purpose, an amino acid sequence consisting of several, most often six (His6), histidine residues was genetically introduced to the N- or C-terminus of the protein, which ensured the affinity binding of the His6-OPH or OPH-His6 enzyme, respectively, to various metal-chelating carriers.[135, 136] The intensity of interactions between the carrier and the genetically modified OPH is determined by the nature of the metal in the carrier and the polyhistidine (polyHis) sequence length and location at a particular terminus of the protein molecule.[137] As the length of polyHis sequence increases, the interaction of the carrier with the enzyme is enhanced, resulting in hindered elution of the protein and successful immobilization to give a stabilized biocatalyst. The increase in the polyHis length in OPH gives rise to enzyme oligomers (tetra- and octamers) and simultaneously markedly increases the enzyme stability.[136]
Of considerable interest was the effect of the length and location (C- or N-terminus) of the genetically introduced polyHis sequence on the catalytic properties of the modified enzyme such as catalytic efficiency, substrate specificity, and the pH and temperature optimum for catalytic activity.[136, 137] It was found that genetic modification of OPH particularly at the N-terminus using polyHis sequences markedly enhances the catalytic performance of the enzyme toward substrates with more bulky substituents at phosphorus such as organophosphorus pesticides, warfare agents, and the products of their hydrolysis (Vx, diisopropyl fluorophosphate, methylphosphonic esters, etc.).[136, 137] The cause for these changes in the properties of enzyme derivatives was identified using computer simulation techniques. It was found that the polyHis-tagging of the OPH molecule involved in the dimer formation induces a conformational change, which results in pronounced opening of the hydrophobic pockets that form the substrate binding site. In the presence of the polyHis sequence, the enzyme conformation is slightly stretched at the outer edges of each OPH subunit forming the dimer (see Fig. 7a); this promotes a minor opening of the pockets, that is, the enzyme active sites that are located more closely to the centre of the dimer molecule. The fabrication of His6-OPH-based recombinant fusion proteins [136] combining the properties of OPH and other proteins and enzymes through their biosynthetic connection into a single molecule with a short amino acid linker further increased the tendency of enzyme – substrate binding pockets to expand and decreased the contact between the OPH subunits in the dimer to the extent of formation of stable monomeric structures with altered catalytic properties.
Thus, using the genetic modification of OPH with polyHis sequences, it is possible
(1) to simplify and accelerate the preparation of highly purified active enzyme by using supermacroporous carriers suitable for flow metal ion affinity chromatography;
(2) to combine enzyme immobilization on affinity carriers with purification to obtain various forms of catalytically active materials to degrade toxic compounds;
(3) to change physicochemical characteristics of OPH (the optimal temperature and pH for activity and stability in different media);
(4) to improve the catalytic properties of the enzyme towards various substrates, thus expanding the substrate specificity of His6-OPH;
(5) to fabricate various fusion proteins containing increasing percentage of enzymes with combined properties in the soluble form upon expression in E. coli cells for the subsequent use to detect and degrade OPC in industry, agriculture, and ecology.
4.3. Post-translational modifications of enzymes
The post-translational modifications (PTMs) of proteins and enzymes underlie the control of protein–protein interactions that determine the vital activity of organisms (Fig. 8). For many proteins, no other functions are known except for the PTM-controlled ability to bind to other biomolecules. Currently, PTM types that determine the final protein function are being studied starting from the synthesis.[138] The biggest problems arise in the study of recombinant proteins, especially when they are expressed in foreign host cells. For example, the results obtained for recombinant eukaryotic proteins synthesized in bacteria are almost inapplicable for studying the functioning of these proteins in eukaryotic organisms. The post-translational modifications can be subdivided into three main types.
![[{"id":"cO9HVFx--I","type":"paragraph","data":{"text":"Main approaches used in protein engineering and examples of protein PTMs: the introduced group is highlighted by a colour; hydrogen atoms are not shown for simplicity, and chemical elements are shown in blue (nitrogen), red (oxygen), white or purple (carbon), and orange (phosphorus)."}}]](/storage/images/resized/0PCqhku27DMD3dHZpFMLLZEUi6LNxKtA0Zz9ZwmY_xl.webp)
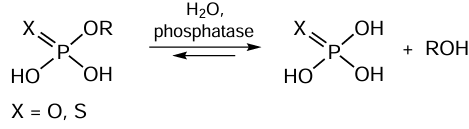
(1) First type modifications: PTMs that control the interactions with other biomolecules and with structural elements of whole cells. There are quite a few such modifications, with protein phosphorylation and dephosphorylation catalyzed by special enzymes, protein kinases and protein phosphatases (Fig. 9), being most popular among them.[109] The introduction of additional negatively charged phosphate groups to serine, threonine, or tyrosine residue changes the protein interaction pathways with other biomolecules. The phosphatase-catalyzed hydrolysis reactions are depicted in the general form in Scheme 6.
![[{"id":"i-jV5pZ5Zf","type":"paragraph","data":{"text":" Structures of human protein phosphatase (<i>a</i>), human alkaline phosphatase (<i>b</i>), and phytase from <i>Aspergillus niger</i> (<i>c</i>). The structural parameters were retrieved from RCSB PDB (codes 6DNO, 1ZED, and 3K4Q, respectively). The catalytically significant Mg<sup>2+</sup>/Zn<sup>2+</sup> ions in the enzyme active sites are shown as spheres."}}]](/storage/images/resized/C1YCXoWKYwSEqaCMZEG6WCqmfwpRlDpR4y7r0dAi_xl.webp)
There are a lot of data on the key role of protein phosphorylation in the regulation of the vital activity in all organisms. A similar process involving sulfation and desulfation at tyrosine residues, which is also accomplished by special enzymes, has been less studied. The development of this research area implies gaining more in-depth knowledge about the role of well-known PTMs [non-enzymatic glycation, glycosylation, oxidation, ubiquitinylation, SUMOylation (SUMO is small ubiquitin-like modifier), and acetylation] and the search for new protein modifications to control their interaction with other biomolecules.
(2) The second type modifications are PTMs that affect the protein structure and change the conditions of protein functioning. These modifications not only alter the interactions of proteins with biomolecules, but also directly influence the catalytic function (change the substrate binding); they affect the amino acid residues of the active site and, as a rule, inactivate the enzymes. However, examples of increase in the enzyme activity upon modification of catalytically important amino acid residues are also known.[139-141]
Modification of allosteric sites may cause both enzyme activation and inhibition. The reversible modification of amino acid residues of the active and regulatory sites can become a significant element in the regulation of catalytic activity of the enzyme and a particular metabolic pathway as a whole. In this field, promising trends are those related to the search for new ways of enzyme protection from irreversible inactivation, which is especially important for biotechnological applications. For example, the most vulnerable SH groups of the Cys residues involved in the catalysis are protected from irreversible oxidation using methods that exist in natural objects, e.g., additional Cys residues are introduced into the enzyme. Investigation of the role of PTMs in the regulation of protein properties allows task-oriented site-specific mutagenesis to produce enzymes with desired properties. For example, the replacement of Cys with serine residues may induce changes in the enzyme function that take place upon SH group oxidation to sulfenic acid (S – OH) group.[142]
(3) The third type modifications are PTMs of amino acid residues in the active site that give rise to a new type of enzyme catalytic activity. This type of PTMs is most interesting, because there are few such examples. In addition, these modifications are closely connected with the effect of moonlighting proteins. These proteins are characterized by the presence of several functions in addition to the main function. Apart from their main catalytic activity, enzymes characterized as moonlighting proteins usually can react with other biological molecules being involved in a variety of processes. For example, they can bind to nucleic acids, thus regulating their transcription or translation, to various signalling proteins, thus inducing apoptosis, etc. Furthermore, while retaining the main catalytic activity, moonlighting proteins can perform other reactions. The additional reactions are usually not very complicated and are closely related to the main catalytic action, being due to the ability of enzymes to bind substrate analogues and to convert them as required. The existence of such moonlighting proteins with diverse functions, including a few types of catalytic activity, puts in question, to a certain extent, the well-known hypothesis of molecular biology, namely, one gene–one protein hypothesis. It should be noted that in most cases, moonlighting proteins fully retain their main function, i.e., they catalyze the reaction for which the enzyme is intended. However, simultaneously, these proteins participate in a few more processes. The post-translational modifications may enhance the ability of moonlighting proteins to perform additional functions. In some cases, after the modification of catalytically important amino acid residues in the active site, the enzyme starts to catalyze an absolutely new reaction to which it was previously inert. Certainly, the main catalytic activity fully disappears. Hence, owing to PTMs, the one gene–one enzyme hypothesis is transformed into one gene–two enzymes. Unfortunately, examples of this sort in which the mechanism has been convincingly proved are almost absent in the literature.
A well-studied enzyme of this type is glyceraldehyde 3-phosphate dehydrogenase (GAPD, EC 1.2.1.12), which oxidizes glyceraldehyde 3-phosphate to 1,3-diphosphoglycerate by reducing NAD to NADH. Modification of the catalytically important Cys residue with GAPD completely inhibits the dehydrogenase reaction. However, GAPD can be easily converted to 1,3-diphosphoglycerate phosphatase upon oxidation of Cys to sulfenic acid residue with hydrogen peroxide, other reactive oxygen species, and even nitric oxide.[143] The appearance of a new type of activity in the enzyme intended for dehydrogenase reaction makes difference for the regulation of glycolysis and energetic processes in the cell. Owing to cleavage of 1,3-diphosphoglycerate, the oxidation and phosphorylation steps in the glycolysis are uncoupled, which is necessary for effective ATP synthesis in mitochondria under aerobic conditions.
The oxidation of Cys residues can also change the function of apurinic/apyrimidinic endonuclease-1 (APE1).[144, 145] The oxidation of SH groups of this enzyme to sulfenic acid groups is accompanied by a decrease in the endonuclease activity and increase in the G-quadruplex affinity. The oxidation results in a change in the function of APE1, which starts to participate in the modulation of transcription processes.
The above data indicate that PTM of one amino acid residue results in the conversion of the enzyme into a protein with a different catalytic activity, thus confirming the existence of one gene – two enzymes model. However, particular examples illustrating a change in the enzyme function upon PTMs are not numerous. Most often, they are discovered accidentally and are not always given due attention. These secondary types of catalytic activity can make an important contribution to the targeted regulation of metabolism and can be used to produce enzymes with new properties by genetic engineering.
4.4. Genetically engineered polysaccharide hydrolases
Cereal grains (wheat, rye, oats, and barley) are widely used to produce animal feed. The feeds contain 13 – 15% non-starch polysaccharides (NSPs) such as cellulose, β-glucans, and xylans, which reduce the digestibility, as they hinder the access of digestive enzymes to nutrients (starch and proteins). Monogastric animals and poultry do not have their own enzymes capable of efficiently cleaving NSPs; therefore, enzyme preparations (EPs) composed of polysaccharide hydrolases (cellulases, β-glucanases, and xylanases) are used as additives in the feed production (Fig. 10). The enzymatic cleavage of NSPs (shown in Scheme 7 as a chain of monosaccharides) increases the uptake of nutrients.[146]
![[{"id":"vQWJdiUNHI","type":"paragraph","data":{"text":"Structures of xylanase from <i>Penicillium canescens </i>(<i>a</i>), endoglucanase from <i>P. verruculosum</i> (<i>b</i>), and β-glucanase from <i>Talaromyces funiculosus</i> (<i>c</i>). The structural parameters were retrieved from RCSB PDB (codes 4F8X, 5I6S, and 6IMW, respectively)"}}]](/storage/images/resized/O6ZG7UiLeiSK7WTQjgErmOc2ecOIGzwU78soKUie_xl.webp)
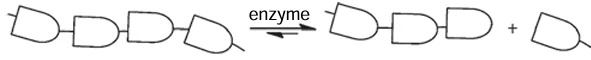
The economically feasible production of enzymes requires high productivity of cells. For this purpose, either mutagenesis and selection of enzyme producers are performed, or genetic engineering methods are used to modify the strains that secrete the target enzymes or complexes of the target enzymes. This genetic modification of producers makes it possible to deliberately change the properties of proteins, for example, to increase their operational stability and catalytic activity towards a number of substrates.[117] Thus, using a few successive stages of induced mutagenesis, the wild type strain was converted to highly productive Penicillium verruculosum strain B221-151, which was further converted, also via mutagenesis, to the P. verruculosum B1-537 strain (ΔniaD), characterized by high secretion of extracellular protein (up to 50 – 60 g L–1). This strain was an auxotroph with a defect in the niaD gene encoding nitrate reductase; this was used as a selection criterion for screening recombinant strains.[147]
The P. verruculosum B1-537 strain produced a set of extracellular cellulases that were superior in activity to the analogues traditionally used for bioconversion of renewable plant raw materials. This strain was used to make recombinant producers of NSP enzymes,[148] out of which heterologous endoglucanase I from Trichoderma reesei (EGI), homologous EGII, and heterologous endoxylanase E from P. canescens (XylE) were chosen.
This gave cells that simultaneously produced EGI and EGII, EGII and XylE, and an XylE-producing strain. Using these strains, the plant Agroferment (https://agroferment.ru) currently produces a number of EPs as additives that improve feed digestibility (Table 3, Table 4). The specific endoglucanase (assessed using CMC) and xylanase activities of these EPs were 1.5 – 3.7 and 1.7 – 3.3 times, respectively, higher than these values for the control EP B1-537 produced with the P. verruculosum recipient strain B1-537 (ΔniaD). The total cellobiohydrolase (CBH) activity of feed EPs (estimated by MCC) decreased 1.3 – 1.8-fold. The control preparation B1-537 included a large amount of exodepolymerases CBHI and CBHII (58% of the total proteins), which is important for cellulose degradation to soluble sugars, but insignificant for a feed additive. In feed EPs, the CBH level decreased ~ 2.5-fold, while the content of endodepolymerases that degrade NSPs substantially increased.
Generally, the data of EP composition were correlated with their specific activity: an increase in the EG and XylE contents resulted in increasing specific CMCase and xylanase activities, respectively, while a decrease in the CBH content led to decreasing specific activity relative to MCC.
Phytates (D-myo-inositol-1,2,3,4,5,6-hexakis-phosphoric acid salts) are a stored form of phosphorus in the seeds of higher plants. The phytic phosphorus content is 60 – 88% of the total phosphorus in grains.[146, 147] Due to very low phytase activity in the digestive system, this form of phosphorus is inaccessible to monogastric animals, who do not digest 60 – 70% of phosphorus from plant-based feeds. In addition, phytic acid binds to Ca2+, Zn2+, Cu2+, Mg2+, Fe2+, and Fe3+ ions and to proteins, starch, and lipids, giving poorly soluble compounds, which substantially reduces the nutritional value of feed. Therefore, phytase (see Fig. 9), which hydrolyzes phytates to inorganic phosphate and myo-inositol, is widely used as a feed supplement.[146]
A highly active recombinant producer of heterologous phytase A from Aspergillus niger (phytase-3) was obtained with the P. verruculosum expression system. Using this producer, the Agroferment plant currently manufactures enzyme preparations Argofit with phytase contents of up to 50% relative to the total protein content and Agrofit Pro (a mixture of phytase and NSP enzymes).
Thus, new high-capacity recombinant producing strains have been developed on the platform of the gene expression system of P. verruculosum microscopic fungus and are used for industrial-scale production of new-generation feed enzyme preparations in Russia.[148, 149]
5. Biocatalysis in medicine
[]
5.1. Biocatalytic synthesis and antibiotic resistance of bacteria
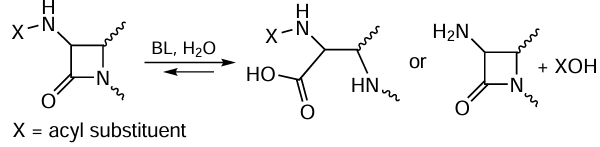
The studies of enzymes for the synthesis (penicillin acylases, PA) and hydrolysis (β-lactamases, BL) of β-lactam antibiotics are of fundamental importance. β-Lactamases synthesized by bacteria are responsible for the resistance of pathogens to antimicrobial drugs of this class (Fig. 11). The hydrolysis reactions catalyzed by enzymes that act on β-lactam compounds are shown in a general form in Scheme 8.
![[{"id":"Bl8_DKzpl9","type":"paragraph","data":{"text":"Structures of β-lactamase TEM-1 from <i>Escherichia coli </i>(<i>a</i>), β-lactamase dimer NDM-1 from <i>Klebsiella pneumoniae</i> (<i>b</i>), and PA from <i>Alcaligenes faecalis</i> (<i>c</i>). The structural parameters were retrieved from RCSB PDB (codes 4OQG, 4RL0, and 3K3W, respectively). The catalytically important Zn<sup>2+</sup> ions in the NDM-1 active site are shown as spheres."}}]](/storage/images/resized/TXw2tCrlLpgIrmv4w7tdnjCYLsR5rDJjVGb4G8Pv_xl.webp)
Owing to the industrial use of PA, the most widely used semi-synthetic penicillin and cephalosporin derivatives have become available; meanwhile BLs help pathogenic microbes to suppress the action of these drugs. The most significant achievements in the PA studies are related to elucidation of the catalytic mechanism, determination of the kinetic and thermodynamic characteristics of enzyme reactions, and analysis of factors that determine the efficiency of transfer of the acyl moiety. A detailed kinetic study of the PA-catalyzed transfer in water allowed to propose an investigation procedure and a kinetic scheme for the quantitative description of experimental data. This approach has formed the basis for comparing the activities of enzymes from various sources and their genetic modifications.[150]
Comparison of various enzyme preparations in terms of the rate of conversion of a selected substrate is improper unless the concentration of enzyme active sites is known. A method for titration of active sites was developed for PA (EC 3.5.1.11); this method can serve to compare enzymes from various sources and their mutants, evaluate the immobilization efficiency,[151] and characterize PA substrate specificity to substrates of various classes.[152] Phenylmethanesulfonyl fluoride, well-known in enzymology as a protease inhibitor used in the isolation and purification of proteins, proved to be applicable for this purpose. Penicillin acylases can efficiently bind this compound to give an enzyme–inhibitor complex, which ultimately results in the covalent modification of the key catalytic Ser residue and enzyme inactivation. The titration method of PA active sites is actively used in various studies (see, for example, [153]).
The key processes involved in the development of antibiotic resistance of bacteria are determined by the action of bacterial hydrolases, that is, penicillin-binding proteins (PBP) and BL. The former are responsible for the synthesis, growth, and division of oligopeptides in the bacterial cell wall and are the key target for β-lactam antibiotics, which are covalent inhibitors of these enzymes. The latter appeared in bacteria during evolution and were meant to inactivate antibiotics via hydrolysis of the C – N bond in the β-lactam ring.[154, 155] Penicillin-binding enzymes are serine hydrolases, while BL can be either serine hydrolases or metalloenzymes.[156, 157]
In the case of serine hydrolases, the first step involves the acylation of the side chain in the Ser residue, whereas in metallo-β-lactamases, a similar process involves the catalytic hydroxide ion instead of Ser residue.[158, 159] In penicillin-binding proteins, the deacylation step is slow, which causes the formation of a long-lived covalent complex of the enzyme with an inhibitor.[160] Conversely, serine BL are characterized by a high deacylation rate, which accounts for the fast degradation of antibiotic molecules. In the case of metallo-β-lactamases, the deacylation step is absent, resulting in further increase in the inactivation efficiency. The resistance develops as a result of mutations in the genes encoding PBP, which deteriorates antibiotic binding, or decreases the acylation rate, or increases the deacylation rate.
Cephalosporin antibiotics belong to the group of β-lactams. Nitrocefin, a chromogenic substrate, which can be used to monitor the reaction kinetics, was synthesized on the basis of cephalosporin.
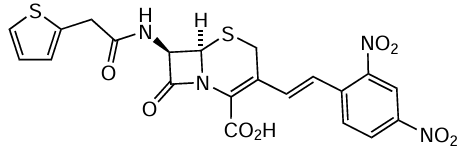
In a study of hydrolysis of nitrocefin in the metallo-β-lactamase L1 active site, three elemental steps of the reaction were identified and accumulation of an intermediate was noted. According to QM/MM calculations, the first step is nucleophilic attack by the hydroxide ion on the carbonyl carbon atom of the substrate, which determines the first (greater) observed rate constant.[161] Then the C – N bond of the nitrocefin four-membered ring is cleaved with a relatively low energy barrier, which is accompanied by the formation of a stable intermediate. The rate-limiting step is the last (third) one, in particular, the proton transfer from the carboxyl group of the catalytic aspartic acid to the nitrogen atom of the antibiotic. These studies provided more detailed knowledge about the sequence of elementary steps with atomic resolution, and the results can be used to analyze the reactivity of related compounds.[162]
Unithiol, a heavy metal ion-binding therapeutic agent, was repurposed for metallo-β-lactamase NDM-1 inhibition.[163] A detailed comparison of the structures of enzyme–inhibitor and enzyme–substrate complexes found by QM/MM calculations showed that effective binding of unithiol is due to recognition of the sulfo group and the conserved carboxy group of the antibiotic by the enzyme active site and thiolate binding by zinc cations instead of the catalytic hydroxide anion. Thus, elucidation of the mechanisms and the elementary steps of enzyme reactions can serve to predict the possible structures of enzyme–inhibitor complexes and to find new inhibitors for key enzymes of pathogens.
5.2. Cholinesterase inhibitors: treatment of Alzheimer’s disease
Alzheimer’s disease (AD) is one of the most common neurodegenerative diseases in elderly people, characterized by progressive loss of memory and other cognitive functions and eventually leading to total disability and death. The lack of effective therapy for AD is largely due to the complex multi-factorial nature of the pathogenesis of this disease.[164] There is a well-known «cholinergic hypothesis» for AD, according to which acetylcholine deficiency correlates with cognitive impairment. This underlies the treatment of AD patients with inhibitors of acetylcholinesterase (AChE) and butyrylcholinesterase (BChE), enzymes that regulate the acetylcholine level in the synaptic space.
As AD progresses, the activity of AChE decreases, while the BChE activity increases, so does its role as a therapeutic target. It is known that selective BChE inhibitors increase the brain level of acetylcholine without the cholinergic side effects characteristic of AChE inhibitors.[165] The discovery of pro-aggregatory properties of AChE towards b-amyloid through participation of the peripheral anionic site played an important role.[164] Since BChE is also associated with various stages of amyloidogenesis,[166] BChE inhibitors are also of interest for the antiamyloid strategy.
Currently, a promising approach to the pharmacotherapy of AD is the design of drugs capable of acting simultaneously on several potential biological targets related to the pathogenesis of this disease, including new aspects of acetyl- and butyrylcholinesterase inhibition.[167, 168]
A successful example of implementation of this approach was the synthesis of original multiligand compounds 1 – 6. These compounds are conjugates of pharmacologically relevant scaffolds that can inhibit both cholinesterases or selectively inactivate BChE. It is important that these compounds are also capable of acting on a number of other important biological targets, which provides their high neuroprotective properties.[168, 169] For example, conjugates 1 – 4 showed a high inhibitory activity against BChE with the half-maximal inhibitory concentration (IC50) in the 1 – 6 μM range and high selectivity compared to AChE and carboxylesterase as the off-target.[170, 171] These results suggest that these compounds might have cognitive-stimulation effect without cholinergic side effects or adverse interactions with other drugs. Conjugates 5 and 6, combining carbazole and aminoadamantane moieties, effectively and selectively inhibit BChE with IC50 = 3 – 15 μM.[172]
Multi-target agents can also be generated by directed modification of known anticholinesterase drugs. In this case, an attractive approach is to improve the pharmacological profile of known drugs such as tacrine or its analogue amiridine by combining them via a spacer with other active pharmacophores.[167, 173-175] The same anticholinesterase drug can be used as a second pharmacophore, and this gives rise to homodimers.[176]
The lead compounds 7a – c distinguished among amiridine–piperazine conjugates effectively inhibit AChE with IC50 in a micromolar range by a mixed mechanism. According to the docking results, these conjugates are bifunctional agents that inhibit hydrolysis of the neurotransmitter acetylcholine and block AChE-induced amyloidogenesis.[174] Homodimers 8 and 9 with two amiridine moieties also effectively inhibit cholinesterases, mainly BChE, being more active than the parent drug.[176] Elongation of the spacer between the pharmacophores results in increasing anti-AChE activity and in the ability to inhibit AChE-induced amyloidogenesis.
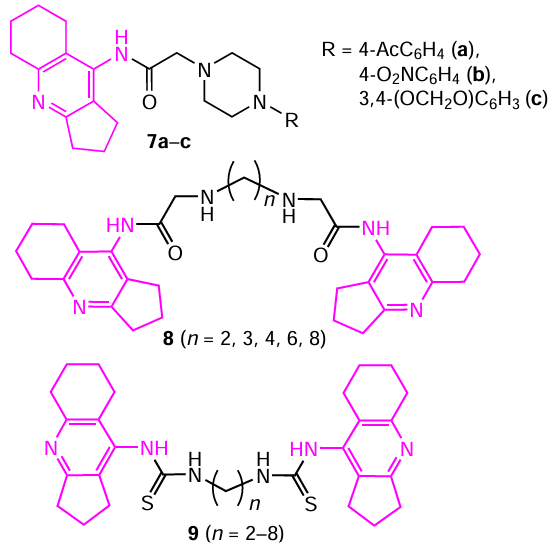
Thus, the recently revealed role of cholinesterases in the pathogenesis of AD not only provides a new look at the development of this disease, but also offers a way to outline new approaches to effective neuroprotective drugs based on the original AChE and BChE activity modulators.
5.3. Biocatalytic processes of DNA repair
Maintaining the integrity of the DNA structure determines the stability of the cellular genome. However, DNA is quite easily damaged by a variety of factors, the most common of which is oxidative stress. A key role in maintaining the genome integrity is played by the DNA repair mechanisms, which remove the damages. Mutations in the genes encoding DNA repair proteins lead to a variety of pathologies, including cancer and neurodegenerative diseases.[177]
DNA repair systems function as supramolecular ensembles of proteins in which some enzymes perform the main catalytic function, while other enzymes and protein factors regulate their activity. Poly(ADP-ribose) polymerase 1 (PARP1) is one of the key enzymes that regulate DNA repair in higher eukaryotic cells (Fig. 12) via protein poly(ADP- ribosyl)ation, which is another important PTM.
![[{"id":"untWCg27J9","type":"paragraph","data":{"text":"Structures of the human poly(ADP-ribose) polymerase 1 (PARP1) (<i>a</i>), histone PARylation factor 1 (HPF1) (<i>b</i>), and human poly(ADP-ribose) glycohydrolase (PARG) (<i>c</i>). Structural parameters were obtained from the RCSB PDB (codes 7ONT, 6M3G, and 6O9X, respectively)."}}]](/storage/images/resized/YgCTag0fEQx0fsx3YsjOn5KbB7tBYYgFokJAIwxY_xl.webp)
In response to DNA damage (single- and double-strand breaks) caused by genotoxic stress, PARP1 catalyzes the synthesis of poly(ADP-ribose) (PAR),[178] a negatively charged branched polymer, using nicotinamide adenine dinucleotide (NAD+) as a substrate (Fig. 13).
![[{"id":"LO_eJV60pZ","type":"paragraph","data":{"text":" Flow chart of the PARP1-catalyzed synthesis of branched ADP-ribose polymer using NAD<sup>+</sup> as substrate in response to DNA damage. The Figure was created by the authors using published data.[[ type=\"anchor\" referenceId=\"16113\" ]] "}}]](/storage/images/resized/Zx2nwwaySOZqmxWZjVmFCN8p4n4DSyhRAChKs4LV_xl.webp)
The PAR macromolecule is covalently bound to the enzyme, giving PARP1 a negative charge and allowing it to dissociate from the complex with the damaged DNA site, thus initiating repair. The PAR formation reaction is reversible: the polymer is cleaved by the enzyme poly(ADP-ribose) glycohydrolase (PARG), which regulates PAR level in the cell. The ADP-ribose residue attached directly to the target protein is stable to PARG and is removed by other enzymes. PARP1 is a member of a large family of 17 proteins that also use NAD+ as a substrate. However, PAR synthesis in the nucleus in response to DNA damage can be catalyzed mainly by PARP1 or by a similar enzyme, PARP2, which was discovered later. Atomic force microscopy (AFM) studies confirmed that PARP1 and PARP2 interact with DNA damage and catalyze the PAR synthesis.[179]
DNA repair may involve RNA-binding proteins.[180, 181] Poly(ADP-ribose) mimics RNA; therefore, it is expected that RNA-binding proteins would bind to it and, hence, these proteins may be incorporated into DNA repair complexes.[182] Among the RNA-binding nuclear proteins, particular attention is attracted by proteins with non-structured domains that are important for interaction with PAR. It includes the FUS protein (FUS is fused in sarcoma); mutations in its gene cause a serious neurodegenerative disease: amyotrophic lateral sclerosis. Under genotoxic stress, this protein interacts with PAR [183] and concentrates on DNA damages.[184] When FUS binds to PAR synthesized by PARP1, membraneless compartments are formed, which can be detected by AFM.[185] This compartmentalization separates damaged DNA from the undamaged DNA array and repair proteins are concentrated on the damages.[181, 185]
In 2016, a new PARP1/2 co-enzyme, histone PARylation factor 1 (HPF1), was found.[186] This protein regulates the activity and specificity of PARP1/2 and forms a joint active site with each of these enzymes.[187] The protein interaction switches the PARylation specificity from the aspartate, glutamate, and other amino acid residues to Ser.[188] Structural and mutational analysis of the HPF1 complex with PARP2 showed that the formation of the joint active site is accompanied by the insertion of the catalytic Glu284 residue of the HPF1 co-enzyme near the glutamate residues of PARP1 and PARP2 involved in catalysis and the NAD+ molecule. This gives rise to an active site able to catalyze the efficient transfer of ADP-ribose to the Ser residue.[187]
Studies of the mechanism of action of HPF1 in the presence of DNA, either free or bound to the nucleosome,[189, 190] demonstrated that this co-enzyme stimulates the initiation of the PARylation. It increases the initially low activity of PARP2 in the presence of specific DNA damage and histone PAR acceptors by a large factor. Thus, PARP2 plays a specific role in response to DNA damage within chromatin.[191] This conclusion is consistent with the recently discovered waves of PAR synthesis and PARylation in vivo. The first wave of PAR synthesis in cells is associated with extensive but short-lived automodification of PARP1, while the second wave is represented by more stable chromatin modification.[192]
The PARP1/2 enzymes are important pharmacological targets for the development of new treatments of human diseases. Inhibition of these enzymes retains them in complexes with DNA breaks, preventing the repair of such damages and leading to the cancer cell death. The production of effective and selective PARP1/2 inhibitors is an intensively developing area of modern medicinal chemistry.[193] All PARP inhibitors currently used in medicine are NAD+ analogues and bind to the NAD+-binding site in the active site of the enzyme, which accounts for their high toxicity and low specificity. Further investigation of PARP functions in cellular processes is needed to find other ways of affecting this target. The most promising approach is to target specific PARP contacts with partner proteins, such as HPF1, which may form the basis of a new approach to antitumour drug design.[194]
Apart from the single- and double-strand breaks detected by PARP proteins, DNA can contain considerable amounts of other, chemically diverse, damages. Thus, cleavage of the N-glycosidic bond of deoxyribonucleosides results in apurinic-apyrimidinic (AP) sites. These sites are also formed as intermediates in DNA base excision repair (BER) after the action of DNA glycosylases, which remove damaged bases from DNA. The apurinic-apyrimidinic sites exist as equilibrium hemiacetal and aldehyde forms (FIg. 14, structures 10, 11). They are unstable and susceptible to 3'-phosphate elimination to give α,β-unsaturated aldehyde 12 (PUA) at the 3'-end of DNA. The same product and 2'-deoxyribo-5'-phosphate 13 (dRP) are formed as intermediates in BER. Since the formation of canonical base pairs is impossible, AP sites are cytotoxic and highly mutagenic.
![[{"id":"e1OTh1fjQL","type":"paragraph","data":{"text":" Structures of modified AP sites and their conjugates"}}]](/storage/images/resized/pQddDCRIIr9MzT0sBOlfvE4jYbu4Jvi72O4goxJE_xl.webp)
As the replicative DNA polymerases reach AP sites, they either release DNA or catalyze the incorporation of dAMP opposite to the damage site. There are specialized (translesion) DNA polymerases that can efficiently incorporate dNMP into such positions; however, the probability of mutation is still very high. Therefore, AP sites in cells must be rapidly repaired. Recently, it has become clear that due to the high reactivity of AP sites, their numerous derivatives are found in living cells. Exposure to various oxidants, xenobiotics, or ionizing radiation gives rise to AP sites oxidized at positions C1' (2'-deoxyribonolactone, DRL, 14), C2' (15), C4' (16, 17), and C5' (18, 1,4-dioxobutane, 19).[195] The apyrimidinic sites readily react with nucleophiles to give a wide range of adducts with low molecular-weight compounds and proteins.[196, 197] Sequencing and mass spectrometry methods confirm that modified AP sites are more numerous than their aldehyde forms.
Since the 1990s, there have been reports that aldehyde AP sites, PUA, and dRP efficiently form relatively long-lived azomethine conjugates 20 with amino groups of diverse DNA-binding proteins: enzymes and structural repair proteins, histones, DNA ligases, integrases, topoisomerases, and so on. These reactions proceed even more easily for oxidized AP sites.[198] Currently, this issue has been most studied for DRL (14), which captures PARP1, Ku antigen, DNA polymerases β and λ, Nth, and OGG1, NEIL1, and NEIL3 DNA glycosylases both in vitro and in the cells pretreated with oxidants. Proteins can also form adducts with AP sites through their thio groups (see structure 21).
Recently, a special way to protect AP sites from spontaneous degradation was discovered,[199] in which the major role belongs to the HMCES protein, which forms thiazolidine conjugate 22 with AP sites upon the reaction between a side substituent and the amino group of N-terminal Cys1 residue. Then this conjugate is removed by the common repair pathway of DNA – protein cross-links accompanied by hydrolysis of the protein part with SPRTN protease. The apurinic-apyrimidinic sites are among the major sources of DNA – protein cross-links in the cell. A method proposed for the preparation of stable conjugates of AP sites with proteins, Schiff bases 20, consists in the NaBH4 reduction of covalent intermediates of DNA glycosidase reactions. The reactions of a large number of DNA polymerases from eukaryotes, bacteria, archaea, and viruses with DNA – protein cross-links have been investigated.[200-202]
The repair of DNA – protein cross-links is closely related to replication; in human cells, it begins with proteolytic degradation of the protein moiety of the conjugate and involves proteasome and specifically acting SPRTN, FAM111A, and DDI1 proteases.[203] Until recently, it remained unclear how the repair of residual DNA – peptide conjugates is completed. The developed [203-205] methods for the preparation of stable AP site/peptide cross-links provided an answer to this question. It was found that these conjugates are cleaved by AP endonucleases and that Nfo and Apn1p enzymes react with any AP site/peptide adducts with equal efficiency, whereas human APE1 preferably forms conjugates involving the ε-amino group of Lys rather than the peptide α-amino group.[177] It is noteworthy that the conjugates of the former type present a much stronger obstacle to DNA polymerases than AP sites or conjugates of the latter type.[206, 207]
Finally, the AP sites and PUA form covalent adducts with low-molecular-weight compounds such as metabolites and xenobiotics, e.g., glutathione (see structure 23) and alkoxyamines (see structure 24). Alkoxyamines are especially promising as therapeutic compounds, because their conjugates 24 are stable to the action of all BER enzymes, which repair AP sites.[208] The simplest representative of this group of compounds, methoxyamine, proved to be promising in clinical trials as a sensitizer of tumours to the temozolomide therapy.
Thus, in recent years, significant advances have been made in the understanding of the role of AP sites in the spectrum of DNA damages, which generate multiple modifications that are repaired in different ways and differently interact with the cell replication system.
5.4. Heme peroxidases: dual role in the human body
Enzymes of the mammalian heme peroxidase family are present in the human body. The major enzymes of this group are myeloperoxidase (MPO, EC 1.11.2.2), eosinophil peroxidase (EPO, EC 1.11.1.7), lactoperoxidase (LPO, EC 1.11.1.7), and thyroid peroxidase (TPO, EC 1.11.1.8) (Fig. 15). These enzymes are grouped together based on the presence of the heme in the active site and the ability to oxidize many substrates under physiological condition.[209, 210] Thyroid peroxidase is expressed in the thyroid gland and plays a key role in the synthesis of the thyroxine and triiodothyronine hormones; LPO is secreted by epithelial cells and has been found in various human exocrine secretions (milk, saliva, lacrimal fluid, etc.) where it has a bactericidal function; EPO is located in the matrix of specific eosinophil granules; and MPO is found in azurophilic neutrophil granules and in the lysosomes of monocytes.
![[{"id":"DXIal1rdlL","type":"paragraph","data":{"text":"Structures of human MPO dimer (<i>a</i>), human EPO dimer subunit (<i>b</i>), and bovine LPO (<i>c</i>). The structural parameters were retrieved from RCSB PDB (codes 5WDJ, 8OGI, and 3I6N, respectively). The catalytically important Fe<sup>2+</sup>/Fe<sup>3+</sup> ions in the enzyme active sites are shown as spheres."}}]](/storage/images/resized/q0HThBRINzQ66NQijwwRYRLjtGh4Fo9tXFMvDWIy_xl.webp)
A simplified scheme showing the functioning of mammalian heme peroxidases is shown in Fig. 16. While reacting with H2O2 , these enzymes transfer two electrons to it, being converted from the native ferric form (Por – Fe3+, where Por is porphyrin) to Compound I (Por·+ – Fe4+=O). Owing to the oxoferryl iron and the porphyrin π-radical cation, the heme of Compound I possesses two oxidizing equivalents. Therefore, Compound I is able to perform two successive single-electron oxidation of substrates via the formation of Compound II (Por – Fe4+=O) and its conversion to the initial, native state of the enzyme (Por – Fe3+), thus closing the peroxidase cycle (see Fig. 16, reactions 1 – 3). Electron donors (designated by AH in Fig. 16) such as ascorbate, nitrite, Tyr, Trp, and numerous aromatic xenobiotics can serve as substrates in the peroxidase cycle.
![[{"id":"UQrE1gARBF","type":"paragraph","data":{"text":"Schemes of peroxidase and halogenation cycles of mammalian heme peroxidases. The Figure was created by the authors using published data.[[ type=\"anchor\" referenceId=\"16145\" ]] "}}]](/storage/images/resized/HDFM98DmHV34a9tT0wVkmmexiwFTMLomYbQExPN0_xl.webp)
Compound I of mammalian heme peroxidases, unlike of that of usual peroxidases, has a unique ability to perform two-electron oxidation of halides (Clˉ, Brˉ, Iˉ) and pseudo-halides (SCNˉ) to the corresponding hypohalous acids, thus closing the halogenation cycle (seeFig. 16, reactions 1 and 4), which is described by the overall equation (3)

In terms of the ability to be oxidized, (pseudo)halides are arranged in the following order: SCN– > I– > Br– > Cl–. However, at physiological pH values and typical plasma concentrations of these anions, MPO preferentially catalyzes the formation of HOCl.[211] Compound I of EPO oxidizes Clˉ only at low pH values, while at pH 7.0, it oxidizes Br–, I–, and SCN– much faster than Compound I of MPO. Meanwhile, at neutral pH, the Br– oxidation by LPO is slow, while that of I– or SCN– is very fast. All four enzymes can oxidize I– to hypoiodous acid (HOI). Since the I– concentration in blood and tissues (except for the thyroid gland) is lower than 1 μM, the oxidation of this anion in the body under physiological conditions can be neglected.
The following conclusions can be drawn from the above data:
(1) the human blood concentration of Cl–is more than 1000 times greater than the concentrations of other (pseudo)halides;
(2) in human blood, neutrophils and monocytes, the cells that contain MPO, account for up to 80% of all white blood cells;
(3) under physiological conditions, only Compound I of MPO is able to rapidly oxidize Cl– to HOCl.
Hence, particularly MPO is the main source of halogen-containing reactants in human blood, with hypochlorous acid (HOCl) being most likely the major species among them. Hypohalous acids behave as potent oxidants, according to Eqn (4), with the halogen atom being an oxidizer.
Therefore, hypohalous acids and their reactive derivatives are commonly referred to as reactive halogen species (RHS).[209-212]
Myeloperoxidase plays an important role in the body protection against pathogens. Neutrophils phagocytize foreign microorganisms, which is accompanied by degranulation involving the fusion of azurophilic and other cytoplasmic granules with the phagosome membrane. Myeloperoxidase, together with other bactericidal proteins, gets into the pathogen-containing phagosome and catalyzes the formation of RHS playing a crucial role in bacterial cell death. The MPO-dependent antimicrobial system of neutrophils is most efficient among bactericidal systems of phagocytes. One more MPO-dependent bactericidal mechanism of neutrophils, which has been called NETosis, involves the formation and extracellular release of mesh-like structures composed of decondensed DNA with incorporated bactericidal proteins, including MPO. These structures are called neutrophil extracellular traps. Having got into the traps, bacteria are killed by antimicrobial agents, including RHS, which are produced during MPO functioning.[213] This is how RHS protect the body from pathogens.
However, the unregulated abnormally high release of MPO from leukocytes upon their activation, degranulation, NETosis, and necrosis and/or an increase in the MPO activity may lead to RHS overproduction. Due to high reactivity and non-specific action, RHS can damage biomolecules, cells, and tissues of the host organism, giving rise to halogenative stress.[209, 210, 214, 215] This stress is characterized by the imbalance between the increased formation of RHS and the decreased ability of the body to remove or neutralize excess RHS.[209, 210, 214, 215] There is a lot of experimental evidence indicating that halogenative stress is responsible for, or at least accompanies, the development of some inflammatory disorders, including cardiovascular, neurodegenerative, autoimmune, cancer, and endocrine diseases.[214, 215, 209-211] The blood of patients with these diseases was shown to contain not only increased concentration (activity) of MPO, but also numerous halogenative stress markers such as HOCl-modified protein, 3-chloro- and 3-bromotyrosines, 2-chlorinated aldehydes, unsaturated phospholipid chlorohydrins, 5-chlorouracil, 5-chlorocytidine, 8-chloroguanosine, etc.[209-211]
Thus, heme peroxidases perform an important bactericidal function by protecting the body from pathogens, but at the same time, they can damage cells and tissues of the host organism, promoting the development of inflammatory diseases. In order to reduce the damaging action of heme peroxidases, while maintaining the bactericidal function, it is needed to develop ways to regulate these enzymes and elucidate mechanisms behind their appearance in the blood.[211] This requires the development of sensitive new-generation methods based on the detection of peroxidases,[211, 216] RHS,[217] and halogenative stress biomarkers, and the search for specific inhibitors [218] capable of maintaining an adequate level of the bactericidal activity of the enzymes, with simultaneous inflammatory containment.[211]
5.5. Membrane and soluble pyrophosphate hydrolases (synthetases) as key energy metabolism enzymes
Pyrophosphate (P2O74–) is a high-energy anion formed in large amounts as a by-product in the biosynthesis of proteins, nucleic acids (NAs), polysaccharides, and many other compounds. There are several hundreds of these reactions and they usually proceed according to general Scheme 9.

To proceed effectively, these reactions require energy that comes from ATP. The Gibbs free energy change (ΔG 0) for ATP hydrolysis to AMP and pyrophosphate (pyrophosphorolysis) is –46 kJ mol–1, and ~ 20 kJ mol–1 is additionally released as PPi is hydrolyzed to phosphate. The overall value is 35 kJ mol–1 lower than ΔG 0 for the cleavage of the terminal phosphoric ester bond in ATP to yield ADP and phosphate (31 kJ mol–1). For this reason, two-step hydrolysis of ATP provides more complete biosynthesis reactions and the possibility to regulate biosynthesis by changing the steady-state concentration of PPi . According to the law of mass action, a decrease in the PPi concentration would stimulate biosynthesis and, conversely, an increase in the PPi concentration would inhibit the process. The steady-state concentration of PPi depends on the activity of pyrophosphatase (PPase, EC 3.6.1.1), which converts PPi to orthophosphate (Scheme 10).
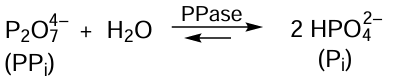
In most organisms, hydrolysis of PPi under the action of PPase is the only pathway for PPi to be involved into metabolism (Fig. 17), because there are no other enzymes using PPi as the substrate. Soluble PPases are classified into two non-homologous families (I and II) with very different spatial structures. Family I occurs in all living organisms, while family II is found only in prokaryotes. With a very rare exception, family I PPases are homodimeric (eukaryotes) or homohexameric (prokaryotes) single-domain proteins (see Fig. 17a). An important feature of family II is two-domain structure with the active site located between the domains (see Fig. 17b).[219]
![[{"id":"M_PuDrmBAG","type":"paragraph","data":{"text":"Structures of human family I (<i>a</i>) and <i>Bacillus subtilis</i> family II (<i>b</i>) PPase subunits and <i>Staphylococcus aureus</i> family II PPase dimer (<i>c</i>). The structural parameters were retrieved from RCSB PDB (codes 7BTN, 2HAW, and 4RPA, respectively). The catalytically important Mg<sup>2+</sup>/Mn<sup>2+</sup> ions in the enzyme active sites are shown as spheres."}}]](/storage/images/resized/HoeEHYSZe0FVO5YjBxKNxXAQieMbVLBOjwF39O59_xl.webp)
In some family II PPases, their single polypeptide has a regulatory region formed by two CBS domains and one DRTGG domain (the domain names were taken from the PHAM database). The CBS domains, found also in many other proteins,[220, 221] strongly bind the adenine nucleotides, with AMP and ADP inhibiting and ATP and diadenosine polyphosphates activating pyrophosphatase.[222] For the active site of family I PPase of yeast cytosol and E. coli, all steps of the catalytic cycle in both directions were characterized and the functions of 13 amino acid residues were determined.[223] The key role in catalysis is played by three or four Mg2+ ions, which activate both the substrate and the nucleophilic water molecule by decreasing its pKa down to ~ 7.[224]
Recent studies demonstrate [225, 226] that the PPase activity in cancer cells is markedly increased. In some diseases such as chondrocalcinosis, it is desirable to increase the PPase activity in order to reduce PPi concentration and prevent crystallization of its calcium salt.[227] For this purpose, methods for PPase delivery to tissues were developed, either by PPase immobilization on nanodiamonds [228] or by conjugation with a transport protein.[229] Family I pyrophosphatase is also present in the mitochondrial matrix, and mutations in its ppa2 gene induce serious mitochondrial dysfunctions in yeast and cause lethal pathologies in humans.[230] Family II pyrophosphatase, which has nucleotide-binding CBS domains, is a good model for elucidation of the CBS protein regulation mechanism. It was found that CBS-PPase is characterized by multiple positive cooperative effects, which are manifested in the catalysis of substrate conversion in the active sites (kinetic cooperativity) and in binding of adenine nucleotides to regulatory sites.[231]
One more family combines integral membrane pyrophosphatases (mPPase; EC 7.1.3.1) present in the membranes of plants, some prokaryotes, and protozoa. They link PPi hydrolysis to the H+ and Na+ transport across the membrane.[231, 232] In terms of the transport specificity under physiological conditions, the mPPase family is subdivided into H+-transporting (H+-mPPase), Na+-transporting, and Na+,H+-transporting (Na+,H+-mPPase) enzymes.[232] All known K+-independent mPPases transport only H+, whereas the K+-dependent enzymes transport H+ or H+ and Na+. All Na+-transporting mPPases are active only in the presence of Na+ ions.[232] Structurally, these enzymes do not resemble any other protein family and represent integral α-helical proteins that span the entirety of the membrane and exist as stable homodimers with molecular mass of ~ 140 kDa [233-235] (Fig. 18). Each dimer subunit (see Fig. 18a) forms an unusual funnel-like structure with a large hydrophilic cavity in the cytoplasmic part and a hydrophilic channel in the membrane part.
![[{"id":"ZXZ70hP9q7","type":"paragraph","data":{"text":"Structure of mPPase and mechanism of cation transport by this enzyme: dimeric Na<sup>+</sup>-mPPase of <i>Thermotoga maritima</i> with a bound pyrophosphate analogue molecule (imidodiphosphate, shown in red) and metal ions (Mg<sup>2+</sup> is shown in green, K<sup>+</sup> is violet, and Na<sup>+</sup> is blue) in the right-hand subunit (code PDB 6QXA); two Asp residues coordinating a nucleophilic water molecule and three residues that form the ion gate are shown (<i>a</i>); schematic view of direct coupling in the proton transport: a water molecule attacks pyrophosphate and gives off a proton for transport across the membrane, while the other proton is absorbed from the cytosol for protonation of the leaving group (phosphate) (<i>b</i>); and the billiard type mechanism of Na<sup>+</sup> transport (the proton formed from the water molecule pushes Na<sup>+</sup> ion into the transport channel) (<i>c</i>). Figures a and c were taken from Baykov et al.[[ type=\"anchor\" referenceId=\"16172\" ]] in accordance with the Creative Commons CC BY licence."}}]](/storage/images/resized/5GLdlDZptHd0BQB40gNF3rCEeiJWmy6ZTxAMipyu_xl.webp)
The cavity is a hydrolytic site containing many protein ligands to bind pyrophosphate and five Mg2+ ions and also two Asp residues, which hold a nucleophilic water molecule. A vertical gated ion channel links the hydrolytic site to the opposite side of the membrane. The structures of H+-mPPase and Na+-mPPase are very similar;[234, 235] the main difference is in the position of the Glu residue, which forms the Na+-binding site in the transport channel of Na+-mPPase.[235, 237] A key achievement in the study of mPPases was the discovery of direct coupling of hydrolysis and transport and determination of the role of the dimeric structure in this mechanism.[235, 236, 238, 239] The mPPase enzyme is the first proton pump operating by the direct coupling mechanism [240] (see Fig. 18b,c) and is found in a number of pathogens: Na+, H+-mPPase and Na+-mPPase are present in bacteria (e.g., Bacteroides fragilis and Clostridium tetani), while H+-mPPase occurs in protozoa (e.g., Plasmodium falciparum and Trypanosoma cruzi). To combat these microorganisms, it is sufficient to inhibit mPPase; therefore, the design of specific mPPase inhibitors is a relevant task.
Pyrophosphate analogues effectively inhibit mPPase, but they are toxic. Therefore, inhibitors that act on targets other than the active site are more promising. Studies in this area have just started. In 2021, Johansson et al.[241] obtained isoxazole and pyrazolo[1,5-a]pyrimidine derivatives with mPPase inhibition constants in the micromolar range, which inhibited the growth of Plasmodium falciparum. The selectivity of these inhibitors is ensured by the fact that no endogeneous mPPase is present in mammals.
5.6. Enzymes in the biocatalytic detoxification
Currently, there is a large number of natural and synthetic toxins the deleterious impact of which on humans and animals can be mitigated by the use of enzymes that catalyze detoxification reactions. Oxidoreductases, hydrolases, and transferases are investigated most often for this purpose [121, 125, 130, 242] (Fig. 19). The reactions catalyzed by typical oxidoreductases and resulting in the oxidation of toxins (RH) are shown in Scheme 11.[121, 125]
![[{"id":"v4WkYgT9SW","type":"paragraph","data":{"text":"Structures of human cytochrome P450 (<i>a</i>), FAD-dependent oxidoreductase from <i>Pleurotus eryingii</i> (<i>b</i>), and laccase from <i>Trametes versicolor</i> (<i>c</i>). The structural parameters were retrieved from RCSB PDB (codes 6DWN, 5OC1, and 1KYA, respectively). The catalytically important Fe<sup>2+</sup>, Fe<sup>3+</sup>, and Cu<sup>2+</sup> ions in the enzyme active sites are shown as spheres"}}]](/storage/images/resized/0LuVj4fVPEvSAZZ1FoqOQymf2C0QJNNyBwvdvmsX_xl.webp)
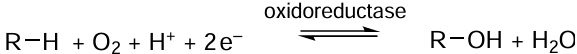
The reactions involved in the destruction of toxins and catalyzed by proteolytic enzymes (Fig. 20) can include amide bond cleavage [130, 242, 243] (Scheme 12).
![[{"id":"LooLTjmVbI","type":"paragraph","data":{"text":"Structures of the dimeric ochratoxinase from <i>Aspergillus niger</i> (<i>a</i>), Zn-dependent neutral protease from <i>Bacillus cereus</i> (<i>b</i>) and subtilisin from <i>Bacillus licheniformis</i> (<i>c</i>). The structural parameters were retrieved from RCSB PDB (codes 4C5Y, 1NPC, and 3UNX, respectively). The catalytically important Zn<sup>2+</sup> ions in the enzyme active sites are shown as spheres."}}]](/storage/images/resized/XPZXDGu7vUoi0A1ae4LThtIivMV8aglllWJF8yK1_xl.webp)

It is known that toxins may function as substrates or inhibitors with respect to enzymes used for detoxification.[121, 122] Cholinesterases (Fig. 21) have been long and actively studied as enzyme antidotes the action of which is based on their non-specific inhibition by various toxic compounds. However, of most interest are those enzymes that provide effective biocatalysis rather than act as single-use bioscavengers. A typical reaction catalyzed by cholinesterases are shown in Scheme 13.
![[{"id":"HiJjMsFhE8","type":"paragraph","data":{"text":"Structures of AChE dimer from <i>Tetronarce californica</i> (<i>a</i>) and monomer subunits of human AChE (<i>b</i>) and BChE (<i>c</i>). The structural parameters were retrieved from RCSB PDB (codes 2XI4, 7E3H, and 6EQP, respectively)."}}]](/storage/images/resized/YumqYBG9lB7z0JNbtG8HBpuY3hPCcsTBfxP2vZld_xl.webp)

Today, the list of toxins subjected to enzymatic detoxification is rather wide, and their chemical nature is quite diverse. Among them, mention should be made of organophosphorus poisons {Vx, soman, O-ethyl-N-[1-(diethylamino)ethylidene]phosphoramidofluoridate},[244, 245] mycotoxins (ochratoxin A,[243] sterigmatocystin,[246] fumonisin,[247] zearalenone [248]), toxic prions,[242] drugs (doxorubicin,[249] carbamazepine,[250] paracetamol,[251] triclosan,[252] cannabigerol [253]), and pesticides (methyl parathion,[254] diuron,[255] transfluthrin [256]). The detoxification often has to be performed in situ (to clean water sources, sewage, soils) and also either in vitro (in industry, to solve engineering tasks of removal of toxins from agricultural raw materials, feed, air, and water used in medicine and for drinking) or in vivo (as antidotes for humans and animals).
Depending on the place and purpose, enzymes are used in various forms, e.g., as stabilized or immobilized products using various materials as supports (fabrics, composites, gels, etc.).[128, 130, 132, 136, 252, 257] The selection of stabilized agents and supports largely relies on the results of molecular modelling, which allows in silico evaluation of the beneficial and adverse effects of immobilization, elucidation of the nature of interactions of protein molecules with supports and stabilizers, and prediction of the properties of the resulting biocatalysts.[129, 130, 136, 252]
Recently, microplastic particles,[258] which adsorb various toxins (pharmaceuticals, mycotoxins, microalgae toxins, prions, etc.), together with other hydrophobic pollutants, have been frequently detected in the environment.[242, 257-259] This problem may be addressed using enzymes that catalyze the complex degradation of toxins, together with microplastics acing as supports.[258] The attention is attracted by systems that combine active and efficient metal-containing chemical catalysts and biocatalysts.[130, 133, 248, 258]
Especially relevant are enzymes that are able to convert not only chemically related compounds (e.g., various organophosphorus poisons and pesticides),[121, 130, 260, 261] but also mixtures of toxic compounds corresponding to various classes (e.g., organophosphorus compounds and mycotoxins, or anaesthetics and pesticides).[126, 129, 136, 244, 250, 253] The use of complex EPs developed for biocatalytic detoxification of various compounds is, in some cases, more advantageous regarding the degree of destruction of not only toxins, but also the products of their transformations.[244, 256] The development and production of recombinant enzymes,[126, 244, 245, 247, 248, 251, 254, 256] in particular for the incorporation into such complexes, provides the basis for technologies required to scale-up the biocatalyst production and expand the scope of practical application of enzymatic detoxification.
Neutralization of peptide and protein toxins is a particularly important task, since such poisons (toxins of animals, microalgae, bacteria, viruses) are widespread in nature.[242] The number of toxic compounds in this chemical group increases due to recombinant proteins, which are actively produced for biomedicine, but these proteins can contain prion amino acid sequences and can be toxic.[242] The approaches to detoxification of illegal drugs using enzymes, including rationally designed proteins, and catalytic antibodies may be promising for further exploration of this field. However, so far, recombinant human transferases and oxidoreductases remain at the forefront of these studies.[242, 253]
5.7. Therapeutic enzymatic nanoreactors
Enzymatic nanoreactors (E-nR), compartments with enzymes in which single or cascade biosynthesis and substrate degradation reactions take place,[262-269] represent the first step towards complex architectures (artificial organelles, cells, etc.[263, 264]). Nanoreactors generally refer to robotic nanodevices and nanofactories that perform mechanical tasks and functions.[265] These therapeutic nanosystems were engineered for detoxification of endogenous toxins [e.g., reactive oxygen species (ROS) and urea] and exogenous poisons (e.g., alcohol), for correction of genetic and metabolic defects, and more recently, for degradation of OPC in vivo. The medical therapy of the OPC poisoning is still unsatisfactory.[266] The bioscavangers that degrade OPC substantially improve the condition of patients with poisoning (Fig. 22).[267, 268]
![[{"id":"FOG3re6lJZ","type":"paragraph","data":{"text":"The principle of action of catalytic bioscavengers, enzymes that interact with OPC with a high turnover number [rate constant for the third step (k<sub>+3</sub>) >> 0], while stoichiometric bioscavengers irreversibly react with OPC (k<sub>+3</sub> close to 0). I is OPC molecule, E · I is enzyme – substrate complex, X is the leaving moiety, EI' is intermediate, P is product"}}]](/storage/images/resized/tmFU0NHYO7ol6P3AdPk6jOgIQ0gkVmN6wpUGRRnC_xl.webp)
An alternative therapy is encapsulation of bioscavengers into nanoparticles (NPs).[269] Enzyme encapsulation into nanocarriers (liposomes, polymer vesicles, silicate NPs, metal-organic frameworks, etc.) leads to increasing stability and more prolonged action and promotes immune response evasion (Fig. 23).
![[{"id":"ZuMSOcNKEF","type":"paragraph","data":{"text":"Modern integrated approaches used to design and fabricate innovative enzyme nanodrugs."}}]](/storage/images/resized/rdEReF04hJma1FRBz3bjwsjPje40MZDbe0Hbni5p_xl.webp)
The decoration of nanoreactor shell provides targeted delivery and crossing the biological barriers. Tightly packed E-nR are stable bioavailable NPs with a size of ≤ 100 nm (at least in one dimension) surrounded by reactant-permeable membrane and containing one or several types of enzymes and cofactors. An important characteristic of E-nR is the enzyme concentration [E] in the nanoreactor.[270] If the enzyme molecular weight is 340 kDa, up to 300 molecules can be encapsulated; this results in ~ 0.001 M concentration inside E-nR. Theoretical description of E-nR has not been completed as yet.[271]
In order to take advantage of E-nR application, it is necessary to select native or genetically engineered enzymes characterized by high activity and to optimize the conditions for fast and safe OPC detoxification in vivo.[272] For example, E-nR was fabricated using phosphotriesterase mutant obtained by directed evolution from the hyperthermophilic archaea Saccharolobus solfataricus,[273] which provided highly efficient degradation of diethyl p-nitrophenyl phosphate (paraoxon, POX): kcat /KM = 1 × 105 M–1 s–1. The in vivo experiments on mouse model of POХ showed good results of using E-nR for preventive and post-exposure treatments. Whereas the half-lethal dose (LD50) upon subcutaneous administration of POX is 1.25 mg mL–1, upon intravenous administration of the enzyme as a part of E-nR, this value increased 16-fold (preventive treatment) and up to 10-fold (post-exposure therapy). The surviving animals showed no impairment of neuromuscular and behavioural functions. The nanoreactor and non-encapsulated enzyme showed similar pharmacokinetic characteristics, with elimination half-lives being 25 ± 2.2 and 22 ± 3.2 min, respectively.
A study of POX biodistribution in the body suggested that the enzyme is exposed on the surface of E-nR.[273] Analysis of animal plasma a month after E-nR injection revealed the presence of antibodies to the injected enzyme. The immune response was not iatrogenic. After the second E-nR injection a month later, the authors observed no significant pathogenic signs in the animals, but did not rule out a cytokine response. The use of E-nR for OPC detoxification in therapeutic studies using a mouse model of POX poisoning demonstrated their efficacy and safety for the first time.[273] The subsequent stages in the development of these studies would involve the optimization of nanoreactors to improve their stability, encapsulation efficiency, and circulation time in blood and to prevent immune response.
5.8. Enzymes and nanomaterials in therapy and drug delivery
In order to solve delivery problem and to prolong the action of both enzymes and small-molecule compounds, it is possible to use inorganic NPs that serve as delivery agents for active ingredients [274-276] in medicine, ecology, and agriculture (see Fig. 23).
Gold nanoparticles (Au-NPs) are chemically inert and non-toxic;[277] they can be synthesized to have any diameter from < 2 nm to 150 nm.[278] The attachment of ligands to Au-NPs is usually due to the high affinity of thiol (sulfanyl) groups to gold.[277] Fluorescent molecules suitable for bioimaging can act as ligands for gold complexes.[279] Gold nanoparticles are used in the photothermal therapy of cancer and for drug delivery in the body.[280]
Silver nanoparticles (Ag-NPs) have antitumour effect themselves and contribute directly to the therapy when they deliver drugs.[281] However, the synthesis of such NPs is labour-intensive and they are toxic; therefore, Ag-NPs are rarely used for drug delivery. In agriculture, they serve as carriers for pesticides and fertilizers and as antimicrobial, antifungal, and antiviral agents.[281]
Silica nanoparticles (SiO2-NPs) are chemically stable, biocompatible, and non-toxic and have a large specific surface area.[282] The NP diameter and pore size can be controlled; therefore, various molecules can be introduced into the nanoparticles. SiO2-NPs are usually synthesized in the presence of surfactants, which stabilize and determine the formation of NP structure.[282, 283] These nanoparticles could be used to deliver anti-cancer agents,[284] in particular, Cre recombinase enzyme, which provides site-specific gene recombination,[285] and antiglaucoma drugs [286] to tissues. TiO2-NPs are easily synthesized, stable, and biocompatible, and they can ensure release of the encapsulated drug under the action of UV light or ultrasound.[287] Tumour imaging and drug delivery to tumours is also performed using ZnO.[288] However, TiO2-NPs and ZnO-NPs are cytotoxic, which restricts their wide use for medical purposes.[287, 288]
Magnetic Fe2O3 or Fe3O4 nanoparticles can aggregate and be oxidized and can be toxic against cells.[289] The NP toxicity can be decreased and colloidal stability can be increased by using polymer coating.[290] In this respect, calcium phosphate nanoparticles (CaP-NPs) are versatile; they are applicable as carriers for polymers or small molecules owing to the reaction of Ca2+ ions with functional groups present in the molecules, e.g., DNA or RNA phosphate groups [291] or with carboxyl groups.[292-294] This feature makes CaP-NPs biocompatible and biodegradable carriers promising for medical applications.[295] Calcium phosphate nanoparticles are obtained by precipitation from solutions by mixing of calcium salts with phosphate ions.[292-294]
Today, CaP-NPs are being investigated as vehicles for ophthalmic drugs meant for topical application.[292-294, 296-298] The encapsulation of the antiglaucoma β-adrenergic blocker, timolol, and the angiotensin-converting enzyme (ACE) inhibitor, lisinopril, which reduce the intraocular pressure (IOP), into calcium phospate NPs enhanced the effect of the drugs in laboratory animals compared to that in aqueous solutions.[298] The antioxidant enzyme superoxide dismutase 1 (SOD1) (Fig. 24) encapsulated into CaP-NPs showed a higher efficiency in the suppression of eye inflammation in immunogenic uveitis in rabbits than an aqueous solution of SOD1.[297]
![[{"id":"MQZ_C8y7Jw","type":"paragraph","data":{"text":"Structures of Cu/Zn-dependent SOD1 dimer (<i>a</i>), catalase tetramer (<i>b</i>), and human nitric oxide synthase dimer (<i>c</i>). The structural parameters were retrieved from RCSB PDB (codes 8Q6M, 8HID, and 4NOS, respectively). The catalytically important Fe<sup>2+</sup>, Fe<sup>3+</sup>, Zn<sup>2+</sup>, and Cu<sup>2+</sup> ion in the enzyme active sites are shown as spheres."}}]](/storage/images/resized/oJeJxoh5vAQo1xJYuVehWdzsAWbPiPOkADwdaGhB_xl.webp)
Even more pronounced effects were observed using CaP-NPs coated with chitosan, which has affinity to mucin on the ocular surface.[292, 293, 296] Encapsulation of enalaprilat (ACE inhibitor) into these NPs resulted in a slow drug release,[293] thus increasing the retention time of the drug in the lacrimal fluid of rabbits after a single instillation,[292, 293] and markedly enhanced and prolonged the effect of decreasing IOP compared to the NP-encapsulated drug without chitosan coating.[293]
Drugs with different types of action can be simultaneously encapsulated into CaP-NPs. Indeed, co-encapsulation of enalaprilat (molecular weight of 348 Da) and SOD1 (32.5 kDa) into chitosan-coated NPs produced a synergistic effect in vivo: the IOP decrease in rabbits 1 h after a single instillation was much more pronounced than the sum of these characteristics attained when each drug was used separately in NPs. This effect was provided by different physiological mechanisms of action of SOD1 and enalaprilat.[292] Comparison of the physiological effects of enalaprilat encapsulated into CaP-NPs, chitosan NPs, and chitosan-coated CaP nanoparticles on IOP revealed a significant advantage of the combination of inorganic core with a chitosan coating.[299] These particles encapsulated the active compound most effectively and reduced IOP. In addition, calcium carbonate particles (CaCO3) should be mentioned, which are, strictly speaking, microparticles, but can also act as vehicles for active substances, including anticancer agents [300] and enzymes such as SOD1 [301] and chymotrypsin.[302] Hence, inorganic NPs are promising carriers of both small-molecule active compounds and proteins.
The conjugation of enzymes stimuli-responsive polymers may provide stable enzyme-based pharmaceutical agents with additional possibility of activity regulation.[270] This line of research was initiated by investigation of the properties of enzymes incorporated into polyelectrolyte complexes via addition to a polycation or polyanion. This approach makes it possible to design an agent based on immobilized enzyme, the quantitative transfer of which from a solution to a precipitate can be easily controlled by minor variation of the environment characteristics (solution pH or ionic strength). This enables regulation of substrate accessibility and related changes in the enzyme activity in living systems containing natural polyelectrolytes (DNA, RNA, polysaccharides, proteins) under macromolecular crowding conditions.[303] For example, there are immobilized enzyme products that perform reactions under homogeneous conditions in the presence of the dissolved biocatalyst, which can be precipitated and separated after the reaction. This is important for biocatalytic transformations of macromolecular or poorly soluble substrates.[304] This stimuli-responsive conjugates of enzymes with polymers, called smart biocatalysts,[305] can be used for drug delivery in the body.[306]
5.9. Enzymes as anticancer agents
The therapeutic use of anticancer enzymes that catalyze the depletion of certain essential amino acids is based on a decrease in the activity of the corresponding amino acid synthetases in some tumour cells. This group of enzymes includes, for example, L-asparaginases (L-ASP), L-lysine-alpha-oxidases, methioninases, arginine deaminases, and so on. L-Asparaginases from E. coli (EcA) and Erwinia chrysanthemi (ErA) are used in the standard therapy of acute lymphoblastic leukaemia, lymphogranulomatosis, and multiple myeloma (Fig. 25). The hydrolysis catalyzed by enzymes that act on amino acids in the general form is depicted in Scheme 14.
![[{"id":"pOoqdyvNT6","type":"paragraph","data":{"text":"Structures of L-ASP tetramer from <i>Erwinia chrysanthemi </i>(EwA) (<i>a</i>), L-ASP dimer from <i>Rhodospirillum rubrum </i>(RrA) (<i>b</i>), and arginase monomeric subunit from <i>Bacillus thuringiensis</i> (<i>c</i>). The structural parameters were retrieved from RCSB PDB (codes 5HW0, 8UOU, and 6NBK, respectively)."}}]](/storage/images/resized/aF2CnF55GCNZCshTaF61wLdNX84qoKX5hxfIppDd_xl.webp)
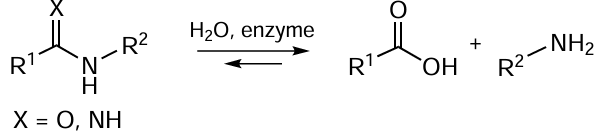
The biochemical mechanism of the anticancer action of L-ASP is to reduce the concentration of L-asparagine, which is needed for the synthesis of proteins and nucleotides for NAs.[307, 308] The rapidly growing tumour cells are deficient in intracellular L-asparagine and are significantly more dependent on exogenous L-asparagine supply than normal tissues. The introduction of L-ASP causes depletion of extracellular L-asparagine, cell cycle arrest, and the subsequent cell death. An important aspect of the anticancer properties of L-ASP is also the receptor-mediated effect of this enzyme on tumour cells.[309]
The main problem involved in the use of L-ASP in oncohematology is low activity of EPs, which entails the use of high doses giving rise to adverse effects. The major factor limiting the use of L-ASP is hypersensitivity, which, according to various data, develops in response to intravenous administration of bacterial enzyme in 20 to 45% of patients. It is obvious that for enzyme therapy of leukaemia, it is reasonable to have a set of L-ASPs differing in the antigenic properties. This accounts for relevance of the development of new L-ASP-based drugs from alternative sources and also contributes to increasing therapeutic efficacy of the enzymes that are already used in medical practice.
We investigated a series of L-ASPs produced by different strains including native and mutant forms.[310-314] It was found that the catalytic activity of L-ASPs measured for asparagine is not always correlated with their cytostatic activity measured on tumour cell cultures. For many L-ASPs, the results were many times greater or smaller than the expected results. The absence of obvious regularities in the deviations of the cytostatic activity of L-ASPs against different cell lines attests to a multi-factorial mechanism of their cytostatic action. One cause for the antiproliferative activity of this enzyme was receptor endocytosis in L-ASP-sensitive tumours. Internalization of enzyme into these cells disturbs protein synthesis even in the presence of excess exogenous asparagine.[308]
Of particular interest is L-ASP from Rhodospirillum rubrum (RrA),[307-309] which has a low homology with EcA and ErA and, hence, one and the same patient would be able to successively take these enzymes if immunotoxicity occurred. The RrA enzyme with a relatively low catalytic activity towards asparagine substrate and an ‘off-optimal’ pH optimum (9.2) shows a high level of cytostatic activity in vitro against a number of cell lines and also in vivo.[307, 308] This is due to the fact that RrA can penetrate into cancer cells and, hence, cleaves asparagine non only in the systemic blood circulation, but also inside the tumour. The L-ASP action in cancer cells appears to be a promising factor that requires further investigation.
Apart from elucidation of alternative action mechanisms of L-ASPs, for implementation of their therapeutic potential, it is also important to develop approaches to increasing therapeutic efficacy and decreasing immunogenicity of enzymes that are already used in medical practice. The most common approach to block the immunogenicity and increase the clearance time from the body is PEGylation (PEG is polyethylene glycol).[307, 315] For example, PEGylation of EcA increases the circulation time in blood from 1.5 to 6 days. For example, the PEG-L-ASP-based drug Oncaspar is used to treat leukaemia in cases of hypersensitivity to L-ASP.
In recent years, a new effective approach to regulate the biocatalytic properties and stability of L-ASPs used in medical practice has been proposed in relation to recombinant agents EwA (from Erwinia chrysanthemi) and RrA (see Fig. 25).[311-318] The approach implies the formation of L-ASP conjugates with branched graft copolymers based on polycations with a variety of compositions and molecular architectures. The polyelectrolyte properties of polymers enable multipoint electrostatic interactions with the protein surface, which allows modulation of the catalytic properties of L-ASP, in particular by shifting the pH optimum of enzyme activity to physiological values.[317, 318] By optimizing the molecular architecture and composition of conjugates, it is possible to achieve an up to five-fold increase in the catalytic efficiency of L-ASP under required conditions. This method made it possible to increase the catalytic activity, thermal stability, and stability to trypsinolysis of EwA and RrA.[311-314] The EwA and RrA conjugates showed a ten times higher antitumour activity in vitro against chronic myeloid leukaemia (K-562) and breast adenocarcinoma (MCF7) cells than the native analogues.[315] The developed technique, formation of conjugates with biodegradable copolymers, provides an increase in the cytostatic activity of EPs against both leukaemia and solid tumour cultures. This fact accounts for high promise of enzymes for the treatment of solid tumours where L-ASPs were ineffective so far.
5.10. Nanocontainers for protein and nucleic acid delivery
Encapsulation of therapeutic agents into structurally diverse nanocontainers is an effective method for manufacturing new dosage forms. The most relevant materials for nanocontainers are polymers (polymer micelles, interpolyelectrolyte complexes) and synthetic and natural lipids (liposomes, lipid nanoparticles, extracellular vesicles, or exosomes) because of convenient functionalization of structures they form.
Currently, despite the advances in the understanding of enzyme functioning and regulation, the problems of enzyme application as drugs remain unsolved.[319] This is caused by both the low stability of enzymes and the frequently occurring side effects, including allergenicity, immunogenicity, and other. A number of techniques have been developed for delivery of macromolecular drugs (biopolymers), proteins (enzymes), and NAs,[320] including encapsulation of active molecules into nanocontainers (e.g., liposomes or polyelectrolyte capsules), microheterogeneous systems,[321-323] and nanoscale lipid and/or surfactant aggregates [324] (see Fig. 23).
Among modern approaches to the fabrication of nanostructures for the regulation and delivery of enzymes and NAs, the following trends are developed most actively:
— an application of stabilized nanoenzymes (protein and polyelectrolyte NPs);
— control of biocatalytic processes by external factors (e.g., low-frequency alternating magnetic field);
— the use of body’s own cells and extracellular vesicles as delivery systems for biopolymers
The encapsulation into nanocontainers based on interpolyelectrolyte complexes proved to be a convenient and versatile solution for both various proteins and enzymes (so-called nanoenzymes) and NAs (polyplexes). In these systems, enzymes retain catalytic activity; the use of these systems improves the cellular uptake of EPs, increases the stability of biomolecules in the body, extends the drug circulation time in the blood, and reduces the immune response.[325]
The spread of antibiotic-resistant pathogens brings about the necessity for the development of new antibiotics and alternative pharmacological strategies.[326, 327] Enzymes of bacterial viruses (bacteriophages), responsible for the degradation of peptidoglycan and cell wall polysaccharides, and protective bacterial capsules come to the forefront. With the goal to develop stable and effective drugs to treat bacterial infections, lysis of pathogens was studied for a number of bacteriophage enzymes (PlyC, LysK, SPZ7, Lys394, etc.) [327, 328] (Fig. 26). Stabilizing compositions of these enzymes with non-ionic surfactants and polyelectrolytes were obtained, with 100% retention of activity against the corresponding pathogen within several months.
![[{"id":"-HgheHKzfq","type":"paragraph","data":{"text":"Structures of LysK endolysin of staphylococcal bacteriophage K (<i>a</i>), PlyC lysin octamer of the streptococcal bacteriophage C1 (<i>b</i>), and human angiotensin-converting enzyme (<i>c</i>). The structural parameters were retrieved from RCSB PDB (codes 4CSH, 4F87, and 1O86, respectively). The catalytically important Zn<sup>2+</sup> ions in the enzyme active sites are shown as spheres."}}]](/storage/images/resized/UTocfUR9JQnuiuFk9MMs7H1KUPUZod309118wlph_xl.webp)
The efficient lysis of Gram-negative bacterial cells, which have an external membrane, appears to be an important process.[327, 329] The external membrane disorder and the access of the endolysin Lys394 of the bacteriophage S-394 (anti-salmonella enzyme) to peptidoglycan were attained using a low-frequency magnetic field.[329-331] Such magnetomechanical approach for the remote control of bioprocesses markedly enhances the efficacy of enzyme action.
Excessive generation of reactive oxygen species (ROS) upon a spinal cord injury give rise to inflammation, the accompanying compression of the injured spinal cord, and neuron death.[332] Nanoformulations that proved to be effective for the treatment of traumatic spinal cord injury were developed using SOD1 and catalase (see Fig. 24) encapsulated into polymer NPs possessing pronounced anti-inflammatory action.[333] The delivery of SOD1 as a nanopharmaceutical to the site of injury significantly alleviated the oxidative stress in injured tissues, extended the circulation time of active enzyme in the blood, and improved the recovery of locomotor function and neural tissue in rats along with reduced inflammation and edema caused by spinal cord compression.
The inflammatory eye diseases remain the most common clinical problem in ophthalmology, leading to tissue degeneration, blurred vision, and even blindness.[334] The composition developed for eye treatment, based on multilayer polyionic NPs containing SOD1, was stable on storage, had a pronounced therapeutic effect without adverse events such as eye irritation, acute, chronic, and reproductive toxicity, allergenicity, immunogenicity, or mutagenicity even when used in high doses.[335] According to preclinical trials, instillations of these NPs into the eye of a rabbit with immunogenic uveitis model were markedly more effective than the use of free enzyme and decreased the inflammation in both external and internal eye structures.[335]
A challenging but important task is to develop effective antioxidants able to overcome the blood – brain barrier. These compounds could significantly reduce the amount of ROS in the brain, attenuate the neuroinflammation, and provide neuroprotection in patients with central nervous system disorders. Many diseases [multiple sclerosis, consequences of stroke, and Parkinson’s (PD) and Alzheimer’s diseases] share a common inflammatory component involving neurodegeneration and subsequent microglia activation, which is accompanied by excessive ROS production.[336] The therapeutic efficacy of loaded with stabilized enzyme macrophages isolated from bone marrow monocytes, which were able to be accumulated in inflamed tissues, was confirmed by a twofold decrease in microgliosis measured by monitoring the expression of integrin alpha-M (CD11b).[337] Furthermore, macrophages remained in the inflammation zone for a long period of time.
In recent years, the targeted cell-mediated delivery of antioxidant enzymes has appeared to be an important element in the development of approaches to the treatment of PD. This can be done using genetically modified host cells transfected with plasmid DNA (pDNA) that encodes the synthesis of a therapeutic protein.[338] Using PD model, stable expression of catalase and subsequent noticeable anti-inflammatory and neuroprotective effects were demonstrated. It was found that upon systemic administration, transfected macrophages release exosomes (extracellular vesicles) with incorporated DNA, mRNA, transcription factor, and encoded protein.[338] The exosomes secreted by various cells are composed of lipid bilayers with an abundance of adhesive proteins and can cross biological barriers.[339] A number of SOD1- and catalase-based nanoformulations loaded into extracellular vesicles ex vivo have been developed. These EPs have a pronounced anti-inflammatory effect and are suitable for the treatment of PD.[340] Exosomal enzyme preparations have been shown to provide significant neuroprotective effects in in vitro and in vivo PD models.[340]
Hence, encapsulation of enzymes and NAs into nanocontainers based on interpolyelectrolyte complexes and exosomes has a significant potential for the development of new therapeutic agents. A key advantage of polymer composites is their tunable biodegradation, which makes it possible to control the duration of drug action. The integration of functional groups, such as vectors or magnetic nanoparticles, into the structure of nanocontainers opens up the way to the fabrication of multifunctional carriers not only capable of controlled drug delivery, but also responding to disease biomarkers and applicable as diagnostic tools (theranostics).
Thus, the systems discussed in this Section form a promising basis for the design of personalized medicine tools.
6. Enzymes in analysis and diagnosis
Enzymes are more often used for analytical purposes than for determining their activity in biological samples. In the determination of parameters of a biological system characterizing the state of the system, enzymes act as molecular recognition elements for diagnosis and/or as components of the modules that amplify the analytical signal. These two functions can be combined and modified by artificial effectors (e.g., aptamers) or combined with physicochemical signal amplification techniques [e.g., surface-enhanced Raman scattering (SERS) and bioelectrocatalysis] and implemented in a parallel format (e.g., as biochips).
6.1. Aptamers in diagnosis and therapy
In the post-genomic era, DNA-operating enzymes (biocatalysts of NA synthesis, repair, restriction/modification, etc.) are actively used in diagnostic systems to identify a nucleic acid. The understanding of NA – protein interactions provides an advantage in the design of such systems. The research along this line received a new impetus from the process of artificial selection of NA ligands, which were named aptamers, for various targets using systematic evolution of ligands by exponential enrichment (SELEX).
Like proteins, aptamers serve as targeting molecules in delivery systems,[341] therapeutic agents,[342] research tools in the development of new therapeutic agents,[343] inhibitors of enzymes (e.g., thermally stable DNA polymerases the action of which needs to be synchronized during analyte amplification), or inactivating ligands (e.g., toxins).[344, 345] The blocking of toxic compounds with aptamers is used to ensure food safety.[346]
There are methods for recognition of antibiotics with aptamers, which are used as discrimenatinal elements in enzymatic systems similarly to antibodies.[347-349] Presumably, fast replacement of real antibodies by aptamers is possible due to a number of properties of aptamers, in particular
— the ability to recognize small molecules (e.g., illegal drugs),[350]
— the application of targeted SELEX to diverse targets,
— preparation via chemical (rather than biotechnological) reactions,
— clear recognition of the target,
— small size compared to antibodies,
— relative stability.[351]
Combination of several recognition modules into the sequence of a single aptamer expanded the scope of their applicability in biosensors by coupling with bioluminescent detection,[352] while additional modifications allowed visualization of aptamers by AFM [353] and by colorimetric detection.[354] The use of aptamers to identify and inactivate unique targets (non-structural prion-like proteins [355, 356]) and for dedifferentiation therapy of brain tumours [357] should be mentioned separately.
Apta- and immunosensors are rarely compared experimentally in determination of the same analyte under similar conditions due to the multiplicity and variability of comparison parameters. The performance of aptasensors in terms of selectivity and sensitivity was illustrated by the thrombin detection system,[358] although the general conclusions about its benefits are questionable.
Aptamers can be used as an alternative to traditional antimicrobial agents.[359] The development of aptamers is a promising strategy to overcome antibiotic resistance. Bacteriostatic aptamers can block the action of bacterial toxins, inhibit biofilm formation,[360] prevent bacterial invasion of immune cells, and stimulate the immune response. The above functions do not require that aptamers penetrate into bacterial cells. This eliminates limitations on the safety and efficacy of targeted NA delivery systems inside bacterial cells. Functioning of aptamers that interact with metallo-lactamases [361] and have exhibited allosteric inhibition of these enzymes [362] requires that they penetrate into the cells. The use of aptamers against pathogens has been discussed for long,[363] but these agents have not yet reached the clinical stage. Currently, only in silico [364] simulation methods for aptamers and quantum chemical computations for the formation of their libraries [365] are being implemented. Combination of the modern experimental methods for selection and for analysis of selected nucleotide sequences by second- and third-generation sequencing methods and the physicochemical characterization of aptamer properties with possibilities of in silico simulation of NA – target complexes accelerate the fabrication of aptamers with desired properties. For example, aptamers for the SARS-Cov-2 virus surface protein were obtained within a year after the disease appeared.[366, 367] The effects of PTMs of this target protein on the efficiency of protein recognition by aptamers have been surveyed.[368, 369]
Thus, research into the production and properties of aptamers in biocatalysis can be considered as preparation for the fight against the next pandemic. These lines of research necessitate the development of methods for NA synthesis, analysis, and screening and computational tools to analyze NA – target complexes, as well as identification of new targets.
6.2. Biochip technology with enzymatic detection for multi-analysis
Enzymes are widely used as detection systems in various bioanalytical methods, with horseradish peroxidase and alkaline phosphatase being used most often for these purposes.[370] The advantages of enzymes are, in particular, ready availability and the diversity of methods for detecting the enzyme activity: colorimetric, chemiluminescent, and electrochemical methods.
A new application of enzymes in medical diagnosis, which has been intensively developed in recent years, is detection of the results of gene multi-analysis on biochips. Biochips represent carriers of a small space carrying immobilized synthetic single-stranded oligonucleotide probes. As supports, various materials are used, most often, glass slides and polymers.[371]
The key feature of biochip technology is the high multiplexity of biochips, which proved to be in demand for the development of molecular methods for detection of antibiotic resistance genes of pathogenic bacteria. Due to the rapid spread of antibiotic-resistant bacteria and the diversity of resistance mechanisms,[372, 373] the development of fast and highly sensitive methods for the simultaneous detection of different resistance genes and their polymorphism has become of prime importance.[374] The first example of using gene multi-analysis for this purpose is represented by biochips with fluorescence detection for genotyping (determination of the set of all single nucleotide polymorphisms) of the most clinically relevant class A BLs, which cause the penicillin and cephalosporin resistance of Gram-negative bacteria.[375]
The biochip technology for solving the problems of laboratory diagnosis of antibiotic-resistant bacteria was further developed in the design of low-density biochips (including 10 to 100 oligonucleotide probes). As an example, consider 3D microarrays based on immobilization of probes in gel microdroplets meant for identification of antibiotic resistance genes of Mycobacterium tuberculosis and key single nucleotide polymorphisms of Neisseria gonorrhoeae.[376] Alternatives to fluorescent probes for DNA targets have been developed, the most popular of which is biotin. Biotin is incorporated into the target DNA and then detected at particular sites of the microarray using streptavidin conjugates with enzymes (horseradish peroxidase or alkaline phosphatase [377, 378]). Among methods used to detect the enzyme activity (colorimetric, chemiluminescent, and electrochemical),[377, 378] the one used most often is colorimetric detection based on chromogenic substrates the enzymatic conversion of which gives insoluble coloured products. The assay results are read using high-resolution optical scanners or cameras, which greatly simplifies the implementation of this method in clinical practice.
A process for manufacturing biochips on porous membrane supports with colorimetric detection based on horseradish peroxidase was developed to detect genes of 11 types of clinically relevant BLs and carbapenemases of various classes in Gram-negative bacteria.[379] The determination is based on direct hybridization assay using one specific probe for each gene. Together with the type of enzyme, it was possible to identify 24 single nucleotide polymorphisms that encode the key substitutions of amino acid residues altering the substrate specificity of class A BLs. The total time of assay after DNA isolation from the bacterial cells was ~ 4 h. The high specificity of identification of mixtures of genes encoding different BLs was demonstrated; this is important for identification of multiple-resistant bacteria.
Check-Points offered colorimetric biochips with enzymatic detection, which were made of porous membranes and placed at the bottom of microtubes. In the first stage of the assay, the DNA – target complexes with two primers were prepared by ligation; then they were amplified by PCR using one of the primers labelled with biotin. A variety of biochips have been developed, including those for determination of methicillin-resistance genes of Staphylococcus aureus and BL genes of the Enterobacteriaceae family.[380, 381] The benefits of this technique include highly specific detection of single-nucleotide polymorphism and highly sensitive determination of DNA, which makes it possible to perform the assay of a clinical sample without additional cell culturing. This technique has a high potential for automation, which is important for practical applications.
One trend in the development of biochip technology is combining a few biochips in the same cartridge or cassette, which simplifies the incubation, washing, and detection steps. Biochips in 8-well strips (ArrayStrips) for determination of 14 types of carbapenemase genes and 7 types of BL genes were developed.[382]
A promising design is biochips placed into 96-well plates. Ulyashova et al.[383] reported a biochip located in two wells of such a plate and meant for identification of 11 types of clinically relevant BLs and carbapenemases and 16 single-nucleotide polymorphisms. The arrangement of biochips in the plate wells substantially increases the number of samples analyzed in parallel, increases the accuracy and reproducibility of the assay, and decreases the total assay time.
A fundamental step forward in the designs of biochips in plate wells was the possibility of quantitative analysis of NAs. This problem appeared because of wide occurrence of multiple-drug resistant and heteroresistant bacteria. In order to study these bacteria and recognize various levels of gene expression in them, it is necessary to determine the change in the concentrations of specific mRNA in bacterial RNA transcripts over a broad range. In 2022, a method for quantification of TEM β-lactamase mRNA with colorimetric biochips in plate wells was developed.[384] For the first time in molecular genetic analysis, quantification was based on the use of a standard BL mRNA samples obtained by in vitro transcription. An advantage of such mRNA samples corresponding to the full-size gene is that they pass all stages of analysis in parallel with the test samples with the same efficiency. The mRNA concentration in the sample is determined using a calibration curve plotted by testing standard mRNA samples of the same gene.
Thus, biochips located in plate wells are characterized by high performance and accuracy and have prospects for the use in clinical laboratories. A fundamental advantage of this method is parallel analysis of several dozens of DNA samples under identical conditions, which allows transition from semi-quantitative analysis of gene transcripts to quantitative analysis. This expands the scope of applicability of biochips to analyze the expressed genes to study in detail the mechanisms of development and ways to overcome the antibiotic resistance of bacteria.
6.3. Enzymes in stimuli-responsive microgels
Efficient and non-destructive immobilization of enzymes is a challenge of modern chemical enzymology and biotechnology.[385-388] Various polymers are widely used as matrices for enzyme immobilization;[389] a special place among them belongs to microgels.[390] Microgels are cross-linked (co)polymers with particle size in the range of 0.05 – 5 μm, with the particles themselves being permeable to solvent molecules and to low- and many high-molecular-weight compounds present in solution. In essence, microgels are high-capacity containers capable of capturing large amounts of various guest molecules.[391, 392] These polymer systems can provide a favourable, water-enriched microenvironment for enzymes, preserving their biological activity and function.
Stimuli-responsive microgels,[390] in particular, dual stimuli-responsive microgels, the properties of which are determined by both the temperature and pH of the environment, are the most promising materials for enzyme immobilization. The examples are copolymer microgels based on poly(N-isopropylacrylamide) (PNIPAM), a thermosensitive polymer with a low critical solution temperature of ~ 32°C. The PNIPAM sub-chains in microgels endow the materials with thermosensitivity, while the pH sensitivity is imparted d by the presence of ionic co-monomer units, which may be protonated or deprotonated depending on the pH of the medium.
The thermosensitivity of PNIPAM-based copolymer microgels manifests itself in the fact that at low temperatures, the microgel particles are in the swollen (highly hydrated) state, while they are considerably hydrophobized and collapse above some critical temperature (volume phase transition temperature).[390] This behaviour is most often reversible, and the microgel particles swell again when the temperature is lowered. Hence, by varying pH and temperature, it is easy to control the hydrophilic-hydrophobic balance of microgels, in particular, the degree of swelling and charge, thereby enabling use of these polymeric objects for modification of various surfaces.[393]
Sigolaeva et al.[393-397] reported the successful application of pH- and thermosensitive cationic copolymer microgels based on PNIPAM for effective modification of conductive surfaces (e.g., graphite and gold) aimed at design electrochemical enzyme biosensor systems (Fig. 27).
![[{"id":"Bjbgt-VjFA","type":"paragraph","data":{"text":"Methods of surface modification exploited for fabrication of microgel-based biosensors (in the middle) and the principles of operation of biosensor systems using choline oxidase, butyrylcholinesterase, glucose oxidase, and tyrosinase for analysis of choline, butyrylthiocholine, glucose, and phenol, respectively (on the sides)."}}]](/storage/images/resized/u20kF0Li68fp8z1kWiPxr7jiGc0INzj0ui8NdCtk_xl.webp)
The principles of operation of the biosensors shown in Fig. 27 can be described as follows:
(1) in the choline biosensor, the enzyme (choline oxidase) converts choline to betaine with simultaneous release of an electrochemically active product, hydrogen peroxide, which then undergoes mediated oxidation at +450 mV potential, thus generating the electrooxidation current (measurable parameter);
(2) in the glucose biosensor, the enzyme (glucose oxidase) converts glucose to gluconolactone with simultaneous release of an electrochemically active product, hydrogen peroxide, which then undergoes mediated oxidation at +450 mV potential, thus generating the electrooxidation current (measurable parameter);
(3) in the phenol biosensor, the enzyme (tyrosinase) converts phenol to catechol and then to o-quinone (electrochemically active product), which is then reduced at a potential of –150 mV and thus generates electroreduction current (measurable parameter);
(4) in the butyrylthiocholine biosensor, the enzyme (butyrylcholinesterase) hydrolyzes butyrylthiocholine to thiocholine (electrochemically active product) and butyric acid; the subsequent mediated oxidation of the former at a potential of +450 mV generates the electrooxidation current (measurable parameter).
The sensitivity and other analytical characteristics of these enzyme biosensors directly depend on the amount of immobilized enzymes and the quality of immobilization. The microgels described in this Section adequately perform the both tasks, providing high capacity and non-destructive physical immobilization.[393-397]
To fabricate the microgel – enzyme coatings on this type of surfaces, a process is successfully used, wherein microgel adsorption is first carried out and then electrostatic binding of the enzyme by adsorbed microgel particles is performed. The microgel adsorption occurs under conditions where mirogel particles are hydrophobized, i.e., considerably dehydrated (elevated temperature) and exist at pH corresponding to their non-charged (or slightly charged) state. Under these conditions, the microgel has the highest adhesion to relatively hydrophobic surfaces. Then the microgel coating is charged by changing pH of the medium, and the electrostatic binding of the enzyme under mild conditions (usually at neutral pH and room temperature) is carried out. The biosensor fabrication under these conditions makes it possible to achieve the best surface modification with microgels (in particular, cationic microgels) and to immobilize a greater amount of the enzyme, thereby providing high sensitivity of the resulting biosensor.[393, 394, 396, 397]
The enzyme immobilization is most efficient if the coating formed at elevated temperature by collapsed microgel particles is brought in contact with an enzyme solution at room temperature. In this case, the electrostatic binding of the enzyme occurs simultaneously with swelling of the microgel matrix, which operates as a sort of sponge that imbibes additional amount of the enzyme.394 At the same time, there is an alternative approach to fabrication of microgel – enzyme coatings, in particular, the formation of the microgel – enzyme complex in solution, followed by its deposition onto the surface.[398]
If the microgel contains primary amino groups, after the formation of the microgel – enzyme coating, covalent binding of the enzyme to the microgel can be performed using any appropriate covalent immobilization methods, thereby considerably improving the operational stability of biosensor systems.[397]
Owing to the network structure of microgels, selective immobilization of enzymes depending on the size of their globules is feasible. For example, a bienzymatic system was proposed, wherein two enzymes, which strongly differed in the size of globules, have different locations in the adsorbed microgel particles.[395] One enzyme (choline oxidase with small globules) proved to be able to penetrate inside the microgel. The other enzyme (BChE, large four-subunit enzyme) did not penetrate inside the microgel, being mainly localized on the surface of microgel particles. Depending on the chosen substrate, it was possible to independently measure the electrochemical responses of choline oxidase (based on choline), BChE (based on butyrylthiocholine), or cascade bienzyme process (based on butyrylcholine).
The BChE immobilization on adsorbed microgel particles enabled development of highly sensitive biosensors for quantitative determination of toxic organophosphorus pesticides, chlorpyrifos and diazinon.[396] For this microgel – enzyme biosensor system, the detection limits of these OPC were < 10 pmol L–1, which is a very good result.
The potential of stimuli-responsive microgels is not limited to the development of biosensors. The demonstration of temperature regulation of the activity of immobilized enzymes appears to be an interesting issue.[399, 400] These systems provide the possibility of changing the enzyme activity as a result of temperature-induced transition of microgel matrix from the swollen to collapsed state. This phase transition of the microgel was shown to decrease the activity of immobilized glucose oxidase, while on lowering the temperature the activity is restored. The cyclic changes of the enzyme activity in repeated heating – cooling temperature cycles confirmed that its multiple regulation is possible.
Thus, the stimuli-responsive microgels have important benefits and advantages for the development of enzyme-based biosensor systems. The use of polymeric objects of this type remarkably improves the analytical performance of biosensors, opens up wide prospects for the design of multi-enzyme systems with different locations of several enzymes. The cascade biosensor systems pave the way for engineering smart biosensors with the possibility of controlling the analytical response of the system by external stimuli.
6.4. Measurement of enzyme activity and study of proteins using surface-enhanced Raman spectroscopy
Raman spectra provide information on the vibrations of atomic groups in molecules, with the intensity of selected bands being used for quantitative analysis. Due to the low intensity of bands, more sensitive types of the technique, such as surface-enhanced Raman scattering (SERS) and surface enhanced resonance Raman scattering (SERRS) in which the signal is enhanced using metal (most often, Au or Ag) plasmon nanostructures, are commonly used in bioanalytical studies.[401] As applied to enzymatic reactions, the high sensitivity of SERS and SERRS methods is relevant, first of all, for measurement of enzyme labels, which are versatile amplification systems used in enzyme-linked immunosorbent assay (ELISA), immunohistochemistry, and more rarely in systems based on hybridization of nucleic acids. Horseradish peroxidase (PO), alkaline phosphatase (ALP) (see Fig. 9), and β-galactosidase (β-GAL) are used most often as the labels. Therefore, highly sensitive SERS-based methods for determining the activity of these enzymes are actually the basis for new-generation molecular diagnostic systems.[401] For analytes such as clinically relevant enzymes in biological fluids, enzymes in food products, and biotechnological recombinant enzymes, the most important factors are the ease, duration and cost of the assay and the correspondence of the analytical range to clinical or production needs. In some cases, the SERS (SERRS) based procedures are considered to be optimal according to these criteria.[402-404]
The development of procedures for determining the enzyme activity using SERS requires finding of compounds (products or substrates of enzymatic reactions) that have high Raman scattering cross-section, bind to the metal surface, and, as a consequence, exhibit intense spectra.[405] The first versatile approach is based on strong interactions of some chemical groups with the surface of noble metals. For example, thiols form a covalent bond,[406-408] while 1,2,3-triazoles, 8-hydroxyquinoline, and 7-amino-4-methylcoumarin are adsorbed due to non-covalent interactions.[405, 409, 410] The appearance of such a group in the molecule as a result of an enzymatic reaction provides selective SERS detection of the product in the presence of excess substrate. This approach is used to determine the activity of various hydrolases: proteases, lipases, esterases (including BChE), β-glucosidase, and OPH.[410, 405-408] For enzyme labels (AP and β-GAL), this principle was tested only by Ingram et al.[409] at the proof-of-concept level.
The second approach to determine enzyme activity widely used in SERS involves a phenomenological search for substrate–product pairs in which the product has a higher affinity for the Au or Ag surface. Most often, this type of detection is used in ELISA (Fig. 28); and most of the systems described to date are adaptations of known colorimetric substrates for such measurements.[402] The best results along this line have been attained using PO substrates: o-phenylenediamine,[411, 412] 3,3',5,5'-tetramethylbenzidine,[413] and leuco dyes,[414] and AP substrate: 5-bromo-4-chloro-3-indolyl phosphate.[415]
![[{"id":"XnMsJzenVs","type":"paragraph","data":{"text":"Basic diagram of SERS-based enzyme-linked immunosorbent assay technique. The immunochemical reactions give rise to an enzyme label (E) on the solid support (polystyrene plate, magnetic particles, <i>etc.</i>) in an amount related to the concentration of the antigen to be detected. The activity of the enzyme label is measured by SERS using one of the approaches described in the text."}}]](/storage/images/resized/gtCHjnoNMceujMi8CWAYlG7M6V2ARcxmZQu17FB4_xl.webp)
In those cases where the enzymatic reaction product does not produce an intense SERS spectrum, it is possible to perform preliminary modification of the metal surface for a chemical reaction giving a SERS active compound in situ.[403, 416, 417] A SERS-based approach for determining the enzyme activity by measuring the substrate consumption has also been reported.[418, 419] In this method, the substrate should produce a more intense SERS spectrum than the product.
The enhancement factor in the SERS spectra markedly depends on the size and degree of aggregation of metal NPs, which forms the basis for another versatile approach to determining the enzyme activity. If the substrate or product causes metal deposition or dissolution, the modulation of the SERS signal of a reporter molecule with intense bands can be used to monitor an enzymatic reaction,[420-422] in particular this may be an implementation of SERS-based ELISA.
Thus, the combination of enzyme catalysis and SERS (SERRS) spectroscopy has formed a rapidly developing area of research, which nowadays has a wide range of approaches and has produced practically significant results as analytical procedures with improved and sometimes unique characteristics.
The use of active substrates comprising Au or Ag films with controlled morphology, which implement the chemical and electromagnetic SERS mechanisms, provides direct investigation and quantification of biomolecules: transport proteins, marker proteins, and enzymes.[423, 424] In recent years, quite a few SERS substrates able to provide high sensitivity and robustness of the method have been developed, and numerous engineering approaches to control of the surface morphology to improve SERS characteristics have appeared.[425-427] A solution of bovine serum albumin (BSA) is often utilized as a test analyte for the development of SERS substrates for protein detection.[428-430] The SERS spectroscopy implemented on planar substrates can also be used to study the dynamic properties of proteins, including aggregation behaviour and changes in the secondary structure.[430]
A variety of SERS-active sandwich substrates based on thin layers of Au- or Ag-NPs deposited on etched ordered structures or on polymer matrices are also actively used for protein detection.[431, 432] For example, the SERS spectra of catalase, cytochrome c, lysozyme, and avidin were recorded in the 50 to 5 mg mL–1 concentration range.[431] Hence, the development of SERS approach to the studies and quantitative determination of enzymes and proteins is associated with the use of technologically advanced methods of substrate formation, which allow serial production and further automation of both the measurements and processing of the results using machine learning methods. To determine the optimal substrate surface characteristics and choose an affordable and reproducible process for the fabrication of substrates with various morphological characteristics, it is necessary to study the plasmonic properties of substrates of various configurations and to know how to predict these factors.
A number of active SERS substrates can be used to measure the SERS spectra of proteins and enzymes without complicated sample preparation. On the basis of experimental studies of various morphologies of Ag SERS substrates, a relatively simple method for substrate formation by electron beam evaporation in vacuum with variable process parameters was proposed.[433] The resulting SERS substrates represented surfaces with nano-sized topography; their efficiency was demonstrated in relation to human myoglobin. In parallel, the sample preparation on these SERS substrates was optimized using ultrasonic and laser treatment of analytes;[434] this additionally amplified the SERS signal in the spectra of analytes by up to two orders of magnitude.
Using SERS substrates,[402] a SERS study of angiotensin-converting enzyme (ACE) was carried out for the first time (see Fig. 26c) in order to develop a procedure for identification the enzyme source. First, the SERS spectra of native and denatured ACEs from seminal fluid were recorded, and the optimal type of SERS substrate for this enzyme was determined.[435] Next, the SERS spectra of ACE from seminal fluid, lungs, and heart were measured, and the source was identified using machine learning techniques.[436] For this purpose, the spectral signals for different sources were separated using linear discriminant analysis, and the result was analyzed by the linear classification method. This gave the main contributions of features (analogues of vibrational bands) that determine the spectral differences. A quantitative determination of proteins was performed to find the extent of glycation of human serum albumin (HSA) in a mixture with non-modified HSA on Ag-based SERS substrates.[437] The arrays of SERS spectra of various types of HSA in different concentrations were treated in a similar way as the spectra of ACE. The results of these studies demonstrated the good prospects of Ag-based SERS-active planar substrates for solving various problems using machine learning methods and automated sample preparation, which is relevant for clinical medicine and automation of diagnosing various diseases.
6.5. Bioelectrocatalysis and new methods of bioelectroanalysis
Bioelectrocatalysis combines the advantages of bio- and electrocatalysis. Research subject matters ‘Bioelectrocatalysis as a New Phenomenon’ and ‘Enzymes as Catalysts of Electrochemical Reactions’ were proposed by I.V.Berezin and S.D.Varfolomeev.[438] Owing to the broad substrate specificity of cytochromes P450 (CYP) as the main enzymes of phase I biotransformation and detoxification of xenobiotics (see Fig. 19), model non-invasive cytochrome P450 systems can be used to study metabolic transformations of drugs and drug interactions and pleiotropic properties of pharmacological agents; obtain new chemical compounds with pharmacological activity; and search for corrector drugs regulating the activity of cytochrome P450 polymorphism.[439] The catalytic action of cytochromes P450 requires redox partner proteins, which transfer electrons from the NADPH electron donor to this enzyme, namely, flavoprotein NADPH-dependent reductase and cytochrome b5 in the case of microsomal systems, or ferredoxin reductase and ferredoxin for mitochondrial and bacterial systems.[439] The unique nature of CYP bioelectrocatalysis is that the reaction is induced by electrons from the electrode, which rules out the need to use the redox partner proteins for cytochrome P450 and reducing co-enzymes for NADPH or NADH.[440, 441]
Cytochromes P450 are target proteins in the development of new drugs. For hormone-dependent cancers, inhibitors of CYP17A1, which catalyzes the 17a-hydroxylase-17,20-lyase reaction, are used in the treatment of androgen-dependent prostate cancer. CYP19 (aromatase) inhibitors behave as anticancer agents and are used to treat breast cancer as an oestrogen-dependent cancer lesion.[439, 442] Among pregn-17(20)-ene derivatives, effective inhibitors of the electrocatalytic activity of CYP17A1 were identified.[441]
Antioxidant agents [ascorbic acid, reduced glutathione, taurine, cytochrome c, and ethylmethylhydroxypyridine malate (Ethoxidol)] stimulate the electrochemical reduction of CYP3A4 and CYP2C9 and decrease the rate of ROS accumulation, thus stabilizing the enzyme. Antioxidants can be used in combined pharmacotherapy to regulate the rate of drug metabolism, especially within the personalized approach to the treatment of patients with genetic polymorphism of the cytochrome P450 isoenzyme.[443, 444]
The polymorphism of enzymes that metabolize drugs is responsible for many undesirable side effects of medication. The stimulating role of antioxidant agents (Mexidol and taurine) on the cytochrome-catalyzed metabolic reactions of diclofenac, a non-steroidal anti-inflammatory drug, was demonstrated. The approach based on bioelectrocatalytic processes is promising for establishing the changes in the concentration range (shift of the therapeutic windows) in the combined use of drugs with different types of therapeutic action.[443-446]
Quantitative methods have been developed to analyze substrates and metabolites of cytochrome P450-dependent electroenzyme reactions using only electrochemical approaches to measure the electrocatalytic activity of these hemoproteins.[447, 448] The use of two potential ranges and two types of electrodes (for cytochromes P450 and for substrates) makes it possible to detect both the electrocatalytic activity of CYP and electrooxidation of substrate or metabolite.[448]
The operation of cytochromes P450 as electrochemical bioreactors for the electroenzymatic synthesis of biologically active compounds still does not receive adequate attention. Electrocatalytic cytochromes CYP3A4 and CYP2C9 as the most functionally significant isoforms were studied considering transition from 2D to 3D sensor via incorporation of the enzyme into regular nanopore membranes of anodic Al2O3 (Anodisc 13) or pore-forming streptolysin O protein placed on the working surface of the electrode.[449-452] In N-demethylation reactions, bioconjugates of cytochromes P450 with flavin nucleotides and riboflavin were used as models of the CYP electron transport chain. The immobilization of bactosomes (bacterial cells simultaneously containing cytochrome P450, reductase, and cytochrome b5) is also a promising approach to enhance the electrocatalytic activity of CYP. These techniques increase the efficiency of electrocatalytic cytochromes P450 by 50 – 200%.[453]
Thus, electrochemical CYP biocatalytic systems can be considered to be a new non-invasive tool for experimental pharmacology applicable to the search for new pharmaceutical agents, study of drug interactions, and analysis of the genetic polymorphism of cytochromes P450.
6.6. Molecular imaging of enzyme activity in vivo
Recently, methods of molecular imaging (MI), concerned with molecular processes in intact living organisms, have been actively developed. The essence of MI systems is to collect signals and form images, which are analyzed to obtain spatial and temporal characteristics of certain molecular processes that take place in the organs and tissues of a living organism and are characterized by high degree of heterogeneity both within an organism and between specimens. The objects of MI investigations are microorganisms, mammalian cells, and laboratory animals (rodents).
The most significant element of the structural organization of microorganisms is the cell wall, the molecular structure of which is largely determined by the biochemical features of particular species. The wall structure can be affected by external conditions in which the microorganism occurs. For example, under unfavourable conditions, the bacterium Mycobacterium tuberculosis can pass to the dormant state; this is accompanied by accumulation of coproporphyrin tetramethyl ester,[454] the concentration of which is correlated with changes in the membrane viscosity.[455] Hence, the endogenous accumulation of methylated coproporphyrins gives rise to non-equilibrium state in the cell, manifested as a significant change in the physical properties of the mycobacterial membrane. When cells switch from one state to another, the following sequence of events occurs in them:
— acidification of the external environment,
— enhancement of porphyrin biosynthesis,
— porphyrin methylation and relocation to the cell wall,
— change in the membrane viscosity,
— respiratory depression,
— change in the metabolic state of the cell.
In the case of mammalian cells, which have a more complex organization, multiple cellular compartments appear, first of all, cell nuclei. The differences in the intracellular viscosity are estimated using the average residence time of the fluorescent probe in the focal volume measured by fluorescence correlation microscopy. Fluctuations in the appearance of a fluorescent molecule in the focal volume can be observed when its concentration is in the nanomolar range. A fluorescent molecule can be generated using green- to red-photoconvertible fluorescent proteins.[456] Using this method, it was found that in the early stage of apoptosis where there are no morphological changes in cell structure as yet, caspase 3 activation is detected considering the lifetime of the cleaved FRET sensor (FRET is the Förster resonance energy transfer). The increase in the retention time in the focal volume suggests that the viscosity increases simultaneously,[457] moreover, throughout the whole cell. However, this increase is non-homogeneous and is most pronounced near the cell nucleus, where complex formation with PARP is possible. Consequently, in mammalian cells, which have a more complex structure than bacterial cells, viscosity changes may be dissimilar in various cell compartments, indicating different localizations of the enzyme activity within the cell.
The quasi-continuous, non-invasive real-time monitoring of cellular and molecular events in organisms is an important goal of modern systems biology. Fluorescent proteins (FP) are the most effective tools for this purpose, because they can be used for long-term measurements in vivo without the additional interferences or stresses caused by the introduction of a fluorescent compound into a body.[458] The most efficient use of FP is the life-time detection of various regulatory proteases such as caspase 3, the role of which in the programmed cell death is well known. The modern methods of fluorescence detection by the excited state lifetime open up new possibilities for real-time imaging of processes both in vitro and in vivo.[459] The FLIM FRET methods rule out the problems associated with the variation of the fluorophore concentrations in biological samples, do not require the calibration procedure,[459] and allow monitoring of caspase-3 activation as an image. This makes it possible to evaluate the heterogeneity of the response to chemotherapy in different parts of the tumour. For example, the image of the A549-TR23K xenograft has a bimodal distribution of lifetimes. This confirms the hypothesis of heterogeneous tumour response to chemotherapy, probably related to the pharmacokinetics of antitumour agents in xenograft models, which is due to characteristics of tumour blood supply. Although the accuracy of fluorescence lifetime measurement does not depend on FP concentration or occurrence of some photochemical reactions, in the living body, there are new factors that are to be taken into account, e.g., the complex trajectory of photons due to multiple scattering. The photon scattering problem can be eliminated by fluorescence tomography based on refractive index differences between tissues. This problem related to the size and location of the tumour in the animal body can be solved by using anatomical and morphological analysis methods such as magnetic resonance imaging. The simultaneous fluorescence tomographic imaging and magnetic resonance imaging can be performed by using a fibre-optic budle. In 2022, model experiments with a simple light guide and a mouse phantom were successfully carried out.[460]
Thus, there are already prototypes of devices that can solve particular MI problems on a real-time basis, i.e., random processes can be detected and non-equilibrium morphological and anatomical changes in tissues can be monitored. However, in the near future, these prototypes should be supplemented with new computational methods that use artificial intelligence algorithms and take into account the real physical picture of processes that occur in living organisms.
7. Conclusion
The modern technological society is based on the development of new processes that provide for highly efficient conversion of matter and energy with virtually infinite resources and minimized impact on the environmental quality. These conditions form the basis for sustainable development. The use of traditional chemical catalysis or catalysis by protein molecules is determined by the reaction conditions. Enzymes cannot operate at high temperatures (> 100°C) where many important chemical reactions are thermodynamically allowed. Meanwhile, enzymes are second-to-none if the reaction is carried out in the protein stability range; moreover, the scope of applications of enzymes is constantly expanding. The use of enzymes and enzyme-based biotechnological processes is now implemented as a pillar of sustainable chemical engineering development. This is due to the fact that enzymes are the most common, readily available, and comprehensively studied catalysts. The chemical and engineering enzymology provide this branch of knowledge with the possibility of producing and using biocatalysts for a variety of applications.
Currently, atomic resolution structural data have been obtained for more than 150 thousand proteins, a large proportion of which are enzymes. A qualitative leap in the understanding of the fundamentals of molecular mechanisms of enzyme catalysis occurred 10 – 15 years ago due to the development of supercomputer technologies and the application of quantum and molecular mechanic methods to simulate the processes in the active sites of biocatalysts. For many significant enzymes, information on the structures of all intermediates and transition states of the catalytic process has been gained, the energy profiles of the reactions have been plotted, the possible values of kinetic characteristics of the reactions have been estimated. Bioinformatics with its set of computational methods plays a key role in the general understanding of the nature of enzyme catalysis. The fundamental breakthrough in the understanding of molecular transformations of the enzyme catalytic sites during the catalytic cycle with determination of the structural details for highly unstable intermediates and transition states makes an invaluable contribution to the general theory of catalysis.
The development of genetic engineering enabled the replacement of single amino acids in the protein molecule; this paved the way towards catalysts with new properties such as thermal stability, catalytic activity, and specificity to reactants. The possibility of targeted modification of protein structure as a rational approach to the design of a protein molecule creates a unique basis for the production of catalysts for many non-trivial reactions. This approach has an enormous potential for development.
Today, the role of biocatalysis in the biomedical technologies and generally in medicine is increasing. The synthesis of modern antibiotics is based on the use of enzymes. Meanwhile, mutating enzymes of pathogenic organisms actively degrade antibiotics, being resistant to them. The antibiotic resistance is a severe problem faced by the treatment of infections; the molecular biocatalytic aspects of antibiotic resistance require further investigation.
Most of modern pharmaceuticals are enzyme inhibitors. The knowledge of the protein structure in the computer simulation provides the possibility of screening chemicals as potential drugs. This rather trivial approach is used by almost any pharmaceutical company in the world. It is being developed in the studies of lactamases that degrade antibiotics and in the search for medications that improve cognitive functions of patients with neurodegenerative diseases. Inhibitors of key enzymes of the human central nervous system are among these agents. The structure, mechanisms of action, and prospects for the design of modern pharmaceuticals are the main challenges for the application of biocatalysis in medicine.
The development of a molecular strategy for the treatment of pathologies requires a fundamental understanding of the biocatalytic mechanisms of particular processes. Fundamentally important enzyme reactions occur in the body upon the change in the DNA molecular structure. Enzymes provide for DNA repair and establish conditions for metabolism functioning in the normal and pathological states. The last decade has witnessed rapid progress in the enzymatic degradation of toxic compounds both in the human body and in its environment, the use of enzymes in therapy (in particular, in the therapy of cancer), and development of new methods for the delivery and use of protein-based drugs. A striking achievement along this line has been the development and use of enzymes that degrade nerve poisons.
Enzymes play a significant and ever increasing role in analytical chemistry. Currently, enzyme-linked immunosorbent assay is a base for medical diagnosis. The bioengineered systems for determination of the blood glucose level based on bioelectrocatalysis with glucose oxidase enzyme are widely used in routine medical analysis. Aptamers, biochip-based multi-analysis, and microarrays based on stimuli-responsive materials are elements of advanced analytical approaches. Analytical methods of SERS signal amplification and studies of proteins by this method are of great practical importance. Further development of bioelectrocatalysis and analytical applications of sensor technologies based on bioelectroanalysis are in progress. New opportunities are offered by the molecular imaging of enzyme activity directly in the body.
Enzymes and biocatalytic technologies are an essential part of chemical engineering, biomedical, and analytical chemistry support of modern society. The production of enzymes accounts for ~25% of the total amount of catalysts in the world. The level of fundamental and applied research of enzymes gives grounds for confidence in the future expansion of the scope of applicability of biocatalysis and increase in the contribution of biocatalysis to sustainable development of society.
8. Acknowledgements
The review was prepared with financial support from the following sources:
— funds of the State Assignments of the M.V.Lomonosov Moscow State University according to subjects Nos. 121041500039-8, 122041100066-7, 123032300028-0, 121011290089-4; 121011990022-4 (for Sections 3, 4.1 – 4.4, 5.1, 5.6, 5.8 – 5.10, 5.12, 6.2 – 6.4);
— Russian Science Foundation (Projects Nos 23-13-00011 and 21-71-30003 for Section 2, No. 21-14-00037 for Section 4.3, No. 21-71-30003 for Section 5.1, Nos 23-74-10040 and 22-14-00112 for Sections 5.3, No. 20-15-00390-P for Section 5.4, No. 23-24-00115 for Section 5.5, No. 20-14-00155 for Section 5.7, No. 24-25-00104 for Section 5.9, No. 22-13-00261 for Section 5.10, and No. 22-24-00424 for Section 6.3);
— Russian Foundation for Basic Research (Project No. 20-04-00915a) and subsidies from the federal budget for the implementation of particular issues of the Federal Science and Engineering Program for the Development of Genetic Technologies for 2019 – 2027 (Agreement No. 075-15-2021-1396) (for Section 3);
— funds of the Ministry of Science and Higher Education of the Russian Federation for implementation of large scientific projects in the priority areas of science and technology development (Project No. 075-15-2024-627) (for Section 5.2) and the Program of Fundamental Scientific Research in the Russian Federation for the long-term period of 2021 – 2030 (Project No. 122030100168-2) (for Section 6.5);
— funds of the State Assignment of the Institute of Chemical Biology and Fundamental Medicine, Siberian Branch, Russian Academy of Sciences (subject No. 121031300056-8) (for Section 5.3);
— funds of the Interdisciplinary Scientific and Educational School of M.V.Lomonosov Moscow State University (Project No. 23-Sh04-45) (for Section 6.1);
— funds of the State Assignment of the N.M.Emanuel Institute of Biochemical Physics, Russian Academy of Sciences (subject No. 122041400080-0) and the Institute of Theoretical and Applied Electrodynamics, Russian Academy of Sciences (subject FFUR-2024- 0007) and the Russian Science Foundation (Project No. 22-14-00213) (for Section 6.4);
— funds of the State Assignment of the Federal Research Centre ‘Fundamentals of Biotechnology’, Russian Academy of Sciences (subject No. 122041100154-1) (for Section 6.6).
The experimental data discussed in this review were obtained, in particular, using the research equipment purchased according to the Lomonosov Moscow State University Program of Development (Sections 5.9, 5.10, 6.3, 6.4). The authors of Section 5.2 are grateful to the Centre for Collective Use of the Institute of Physiologically Active Substances, Russian Academy of Sciences (FFSG-2024-0021), for the provided equipment.
9. List of abbreviations and symbols
ΔG 0 — Gibbs free energy change,
KM — Michaelis constant,
kcat — catalytic constant,
ACE — angiotensin-converting enzyme,
AChE — acetylcholinesterase,
AD — Alzheimer’s disease,
AFM — atomic force microscopy,
Amp — ampicillin,
AMP — adenosine triphosphate,
L-ASP — L-asparaginase,
AP (sites) — apurinic-apyrimidinic (sites).
ALP — alkaline phosphatase,
APE1 — apurinic (apyrimidinic) endonuclease-1,
ATP — adenosine triphosphate,
BChE — butyrylcholinesterase,
BER — base excision repair,
BL — β-lactamase,
CBH — cellobiohydrolase,
CboFDH — formate dehydrogenase from the yeast Candida boidinii,
CES — carboxylesterase,
ChE — cholinesterase,
CMC — carboxymethyl cellulose,
CP — coenzyme preference,
CYP — cytochrome P450,
DAAO — D-amino acid oxidase,
DASPO — D-aspartate oxidase,
E — enzyme,
EC — enzyme classification,
E-nR — enzymatic nanoreactors,
EcA — L-asparaginase from Escherichia coli,
EGI — heterologous endoglucanase I from Trichoderma reesei
EGII — endo-β-1,4-glucanase II,
ELISA — enzyme-linked immunosorbent assay,
EP — enzyme preparation,
EPO — eosinophil peroxidase,
ErA — L-asparaginase from Erwinia chrysanthemi,
FDH — formate dehydrogenase,
FP — fluorescent proteins,
FRET — Förster resonance energy transfer,
β-GAL — β-galactosidase,
GAPD — glyceraldehyde 3-phosphate dehydrogenase,
HAA — α-D-amino acid ester hydrolase,
HPF1 — histon PARylation factor,
IC50 — half-maximal inhibitory concentration,
IOP — intraocular pressure,
LD50 — half-lethal dose,
LPO — lactoperoxidase,
Luc — luciferase,
MPO — myeloperoxidase,
MCC — microcrystalline cellulose,
MI — molecular imaging,
mPPase — membrane pyrophosphatase,
NAD — nicotinamide adenine dinucleotide,
NADP — nicotinamide adenine dinucleotide phosphate,
NhaDAAO — D-amino acid oxidase from archaea Natrarchaeobius halalkaliphilus AArcht4,
NhyDAAO — D-amino acid oxidase from bacterium Natronosporangium hydrolyticum ACPA39,
NA — nucleic acid;
NP — nanoparticle,
NPS — non-starch polysaccharide,
OpaDAAO — D-amino acid oxidase from yeast Ogataea parapolymorpha DL-1,
OPC — organophosphorus compounds,
OPH — organophosphate hydrolase,
PA — penicillin acylase,
PAR — poly(ADP-ribose),
PARG — poly(ADP-ribose) glycohydrolase,
PARP1 — poly(ADP-ribose) polymerase 1,
PD — Parkinson’s disease,
PBP — penicillin-binding proteins,
PCR — polymerase chain reaction,
PEG — polyethylene glycol,
PNIPAM — poly(N-isopropylacrylamide),
PO — peroxidase,
Por — porphyrin,
POX — paraoxon,
PPase — pyrophosphatase,
PPi — pyrophosphate,
PTM — post-translational modification,
PseFDH — formate dehydrogenase from bacterium Pseudomonas sp.101,
PUA — α,β-unsaturated aldehyde,
QM/MM — quantum mechanics/molecular mechanics,
RrA — L-asparaginase from Rhodospirillum rubrum,
RHS — reactive halogen species,
RM — random mutagenesis,
ROS — reactive oxygen species,
SA — serum albumin,
SauFDH — formate dehydrogenase from the pathogen Staphylococcus aureus,
SELEX — systematic evolution of ligands by exponential enrichment,
SERS — surface-enhanced Raman scattering,
SERRS — surface-enhanced resonance Raman scattering,
SNP — single nucleotide polymorphism,
SOD1 — superoxide dismutase 1,
TPO — thyroid peroxidase,
XylE — heterologous endoxylanase E from Penicillium canescens.
References